Leveraging CLIP for Visual Question Answering
Recently, models (like CLIP) pre-trained on large amounts of paired multi-modal data have shown excellent zero shot performance across vision-and-language (VL) tasks. Visual Question Answering is one such challenging task that requires coherent multi-modal understanding in the vision-language domain. In this project, we experiment with CLIP and a CLIP-based Semantic Segmentation model for VQA (visual question answering) task. We also analyse the performance of these models on the various types of questions in the VQA dataset. We also experiment with publicly available multilingual CLIP on multilingual VQA, which is extremely challenging considering the sparse nature of some languages. Through all of our experiments, we intend to show the zero-shot capabilities and suggest ways in which these models can be creatively used in a challenging task like VQA.
- Background
- Motivation
- Problem Statement
- Theory
- Dataset
- Methodology
- Experiments and Results
- Observations
- Challenges and Limitations
- Future work
- Conclusion
- Code repository
- References
Background
Contrastive Language Image Pre-Training (CLIP) is a neural network architecture that efficiently learns visual concepts from natural language supervision. While standard image models jointly train an image feature extractor and a linear classifier to predict some label, CLIP jointly trains an image encoder and a text encoder to predict the correct pairings of a batch of (image, text) training examples. At test time, the learned encoders synthesize a zero-shot linear classifier by embedding the names or descriptions of the target dataset’s classes. The Visual Question Answering (VQA) task combines challenges for processing data with both Visual and Linguistic processing to answer basic ‘common sense’ questions about given images. Given an image and a question in natural language, the VQA system tries to find the correct answer using visual elements of the image and inference gathered from textual questions. Deep Modular Co-Attention Networks (MCAN) is one of the state-of-the-art VQA models that has won the VQA 2019 challenge. There has also been prior work on leveraging semantic segmentation to improve the performance of VQA models. Very recently proposed language-driven semantic segmentation (LSeg) model especially has generalized well to previously unseen categories without fine-tuning and without even using a single training sample of that category.
Motivation
VQA is a very challenging language-vision task which requires a rich understanding of both text and images. CLIP has been trained on a wide variety of images with a wide variety of natural language supervision that’s abundantly available on the internet. Hence, it is much more representative and has shown good zero-shot capabilities on various vision tasks like image classification, image generation and also vision-language tasks like image captioning. Although the transformer-based language models are highly expressive, they are relatively weak at zero-shot ImageNet classification. Both the image and text encoder’s of CLIP model have been non-trivially transferred to most tasks and is often competitive without the need for any dataset-specific training. The encoders used in VQA models are trained on only a small set of manually annotated data which is very costly to collect. Hence, using the encoders of a large-scale pre-trained model like CLIP encoders in VQA models could lead to better generalization performance. Semantic segmentation has been shown to have improved the performance of VQA by adding additional features to the VQA encoders. Most of the VQA models use Faster RCNNs in their visual encoders, which extract bounding boxes. As the bounding boxes are located around countable objects, information on the amorphous regions in the background is not reflected. Hence, augmenting the semantic features into the VQA models would potentially fill this gap. Answering the number-based questions in VQA is the most challenging part, and hence semantically segmenting the image and counting the number of objects in the segmented map could be beneficial in answering this category of questions.
Problem Statement
We have experimented on the vision and language encoders of the MCAN VQA model with the pre-trained vision and language encoders of CLIP and studied the performance improvement on various categories of questions. We have also studied the effect of semantic features obtained using language-driven semantic segmentation on the CLIP+MCAN VQA model. Number-based questions are particularly the most challenging category of questions in a VQA task. Hence, we focused on solving them in a different way. We have generated the semantic maps of the images using LSeg in a zero-shot fashion with a keyword that is extracted using the template matching technique. Following that, we used image processing techniques to count the number of objects of the extracted keyword in the generated segmentation map. We also experimented with Multilingual CLIP on Multilingual VQA.
Theory
Contrastive Language Image Pre-Training (CLIP)
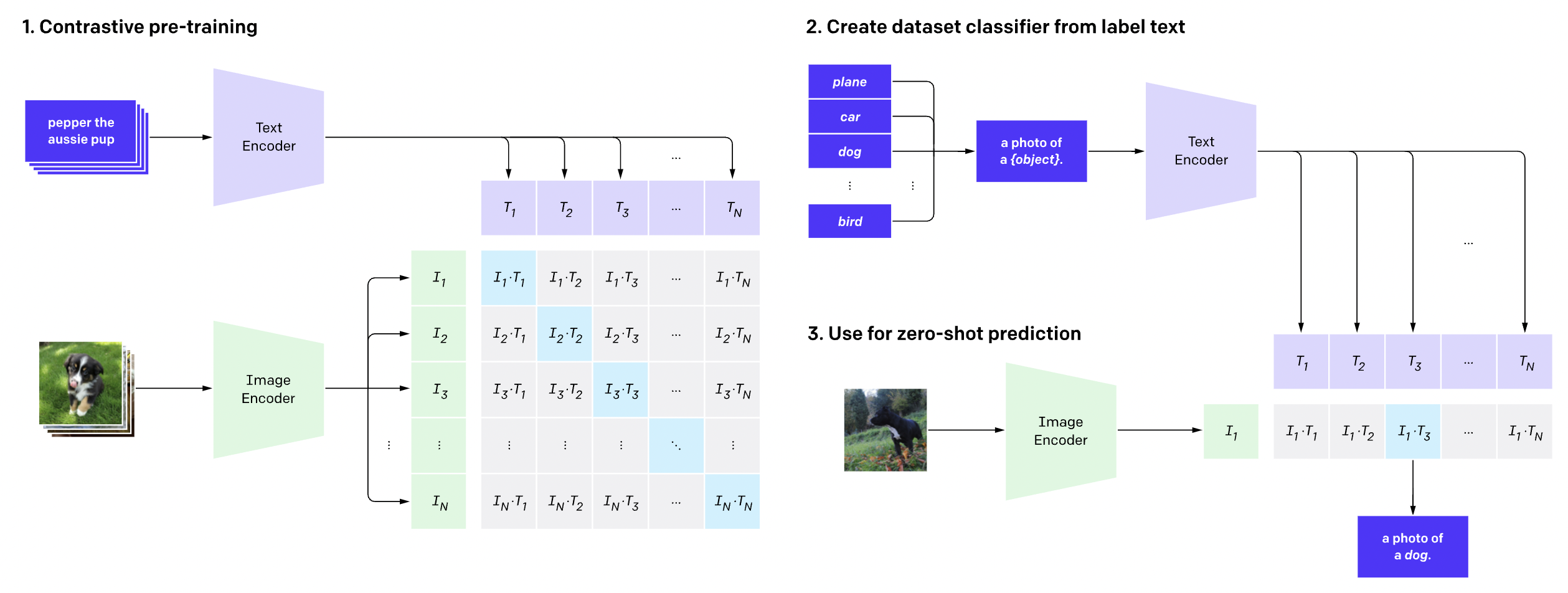
Fig 1. CLIP's image, text encoders and it's application for zero shot prediction.
The architecture of CLIP is shown in Figure [1]. Pre-trained CLIP has learnt a wide range of visual concepts from natural language supervision and has exhibited very good zero-shot capabilities on several vision and language-vision tasks. It has, in fact, given state-of-the-art results on most of those tasks. Most of the available vision models perform well only on a single task and need sufficient fine-tuning to adapt to new tasks. They might also not generalize well to the same task on a different dataset. However, the CLIP model has been trained on a wide variety of images and text (400 Million pairs) that is abundantly available on the web. Hence, the image and text representations obtained using CLIP are much more generalized. It is also highly robust and efficient as it has been pre-trained on unfiltered, highly varied and noisy data. Given a batch of N (image, text) pairs, CLIP is trained to predict which of the N × N possible (image, text) pairings across a batch actually occurred. To do this, CLIP learns a multi-modal embedding space by jointly training an image encoder and text encoder to maximize the cosine similarity of the image and text embeddings of the N real pairs in the batch while minimizing the cosine similarity of the embeddings of the N*N − N incorrect pairings. The image encoders used in CLIP are ResNet/Visual Transformer based and the text encoders used are transformer based. After pre-training, natural language is used to reference learned visual concepts (or describe new ones), enabling zero-shot transfer of the model to various downstream tasks.
Multilingual CLIP (M-CLIP)
It is a publicly available variant of CLIP with text encoders for any language with the same image encoders. The text encoders are used from huggingface library which are trained on over 100 languages. We use this model for the multilingual VQA task. We call this model M-CLIP in all future references.
Deep Modular Co-Attention Networks (MCAN) VQA
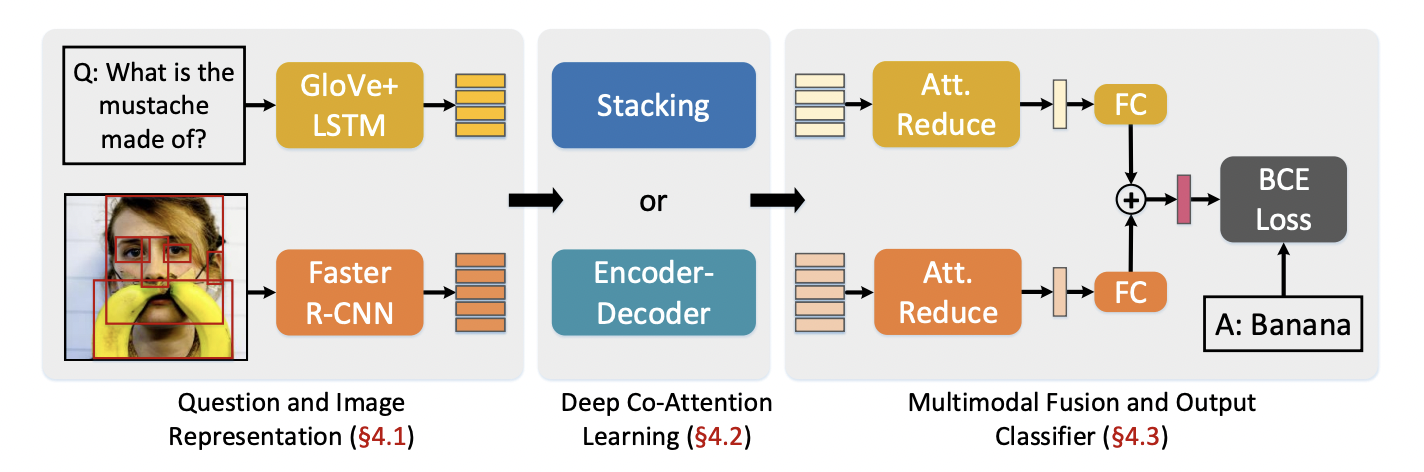
Fig 2. Overall Architecture of MCAN.
The architecture of MCAN VQA is shown in Figure [2]. VQA is a multi-modal task that requires a simultaneous understanding of both the visual content of images and the textual content of questions. The image representations in MCAN are generated using Faster R-CNNs and the text representations are generated using GloVe+LSTM. These embeddings and then passed to a deep co-attention block. The deep co-attention learning block comprises several Modular Co-Attention layers cascaded together in depth, forming models that support more complex visual reasoning. Simultaneously learning co-attention for the visual and textual modalities can benefit the fine-grained representation of the image and question, leading to more accurate prediction. Each MCA layer is made up of self-attention and co-attention units shown in Figure [3]. The self-attention units model dense intra-modal interactions i.e. the word-to-word representations for questions and region-to-region information for images. The MCA layers can be cascaded together either using a stacking model or an encoder-decoder based model shown in Figure [4]. In the stacking model, the output of one MCA layer is fed as the input to the next MCA layer. Whereas, in the encoder-decoder model, the input features of each GA unit are the question features generated as output of the last MCA layer. The output image and question features obtained from the deep co-attention learning block contain rich information of attention weights over image regions and question words. Hence, they are passed to an attention reduction block (two layer MLP). The attended features are then fused together to a single feature which is then used for training using binary cross-entropy loss function.
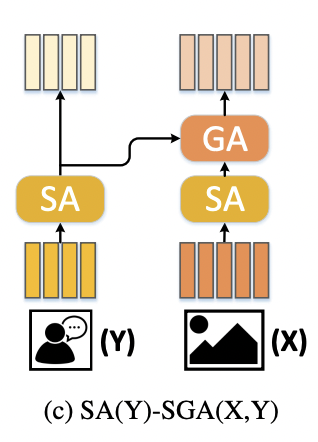
Fig 3. Self-Attention and Co-attention Units in MCAN.

Fig 4. Different types of cascading of MCA Layers.
Language Driven Semantic Segmentation (LSeg)
The architecture of LSeg is shown in Figure [5]. LSeg is a novel method that semantically segments an image based on the input labels fed to it as input. It uses a state-of-the-art pre-trained text encoder of CLIP as its text encoder to compute the embeddings of descriptive input labels. And it uses the dense prediction transformer (DPT) as the image encoder to compute per pixel embeddings of the input image. The LSeg model is trained with a contrastive objective to align pixel embeddings to the text embedding of the corresponding semantic class. It achieved very competitive zero-shot performance when tested on unseen labels. In order to create training datasets, human annotators must associate every single pixel in thousands of images with a semantic class label. This is a labor intensive and costly task, even with small label sets. A word-pixel correlation matrix is obtained by computing the similarity between the text embeddings and the per-pixel image embeddings. The objective is to maximize the similarity of the per-pixel image embeddings with its corresponding ground truth text embedding. Similar to standard semantic segmentation models, the per-pixel softmax with cross-entropy loss is minimized during the training phase. Due to memory constraints, the image encoder predicts pixel embeddings at a lower resolution than the input image resolution. Hence, an additional post-processing module is used to spatially regularize and up sample the predictions to the original input resolution.
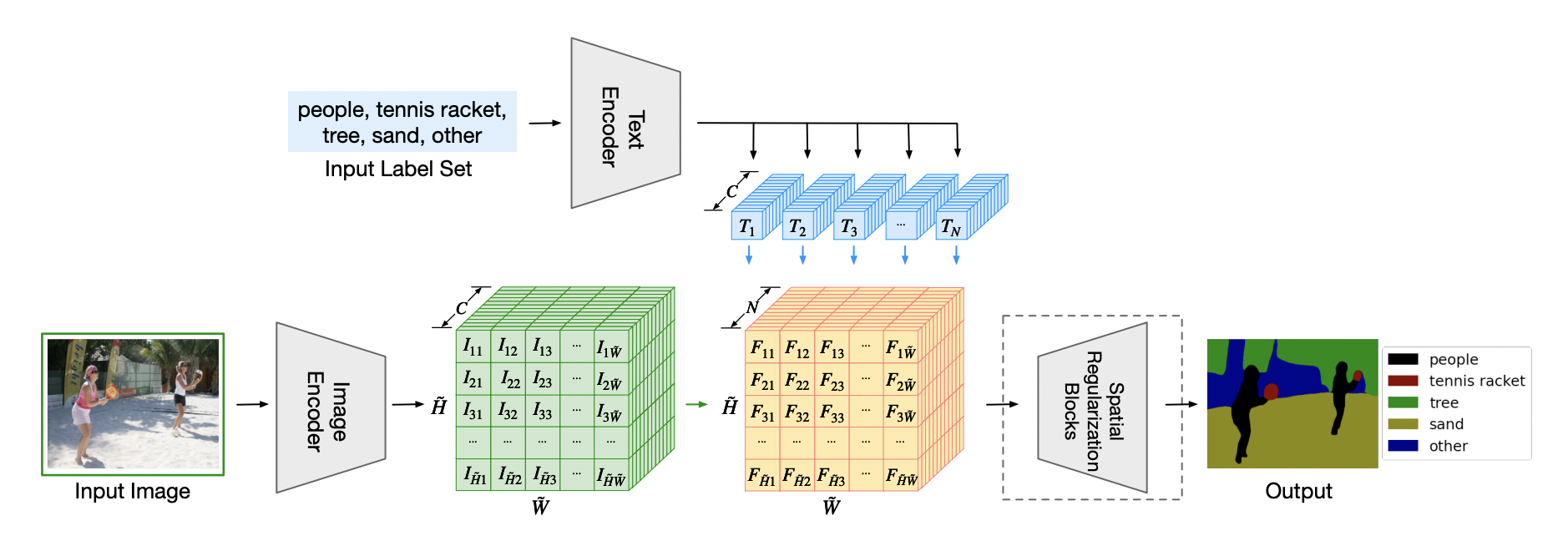
Fig 5. Overall Architecture of LSeg.
Dataset
We used the VQA 2.0 dataset that contains open-ended questions about images. These questions require an understanding of vision, and language to be answered. It comprises both real and abstract scenes. The dataset has 443,757 training, 214,354 validation, 447,793 test images of real scenes and 60,000 training, 60,000 validation, 60,000 test images of abstract scenes. It has 3 categories of questions: number based, yes/no and other. Few samples from the dataset are shown in Figures [6] and [7].
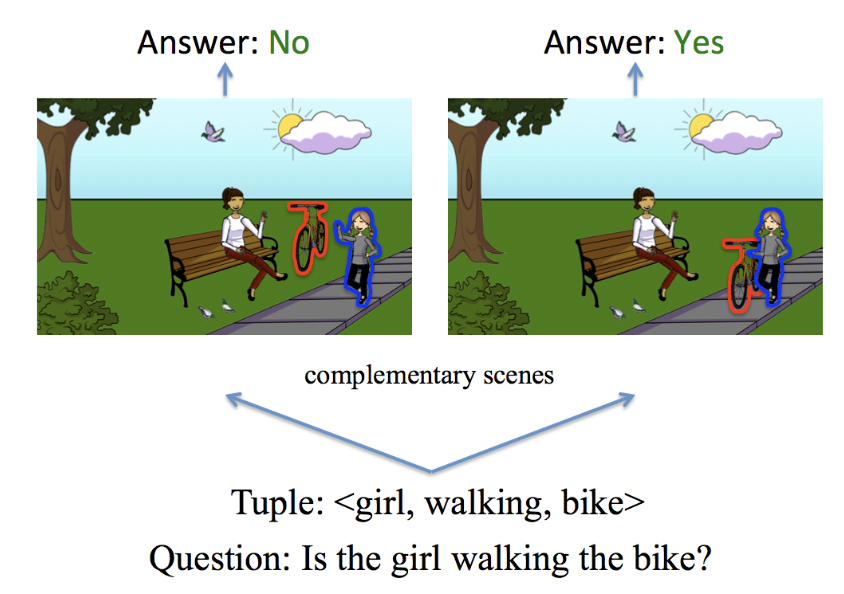
Fig 6. Examples of VQA 2.0 dataset (Number Type and Yes/No Type Question).

Fig 7. Examples of VQA 2.0 dataset (Other Type Question).
We also performed experiments of Multilingual CLIP-based VQA Models on Multilingual VQA using multilingual variants of the VQA 2.0 train and validation sets available here. These sets contain four times the original data which was originally in English in other languages like French, German and Spanish, translated using Marian models.
Methodology
Why CLIP for VQA?
The image, and text encoders used in most of the VQA models are pre-trained only on small sets of image and text data, respectively. Hence, they have less multimodal representation knowledge and do not generalize well on new datasets and also do not have zero-shot capabilities. VQA task on the other hand requires a very rich understanding of both image and question. So, using the encoders of a large scale pre-trained model like CLIP would lead to a better generalization performance and aid in exhibiting zero-shot capabilities.
Why LSeg for VQA?
Semantic segmentation has proved to improve the performance of visual question answering tasks. The image encoders in most of the VQA models are Faster RCNNs which detect bounding boxes around the objects of interest. They fail to capture the information in the amorphous regions of the background which might be crucial for a VQA task. Semantic features of an image would, however hold this information that could be useful for VQA. LSeg has shown good zero-shot performance, and it also uses a pre-trained CLIP’s text encoder. So, we can directly use the pre-trained LSeg model on our dataset to do semantic segmentation or obtain the semantic features from the images. The number based questions in VQA gave poor performance even with state-of-the-art VQA models. Counting the number of objects present in a semantically segmented image could be helpful here.
CLIP + MCAN (Method 1)
Initially, we replaced the pre-trained MCAN’s image encoder (Faster RCNN) with the image encoder of CLIP (with ResNet-50 backbone) and tried direct inference and training + inference on that setting. Then, instead of replacing the image encoder completely, we tried augmenting the data so as to capture the image features using both CLIP’s image encoder and Faster RCNNs. And then, we replace the MCAN’s text encoder (GLoVe + LSTM) with the text encoder of CLIP. In this setting also we tried only inference and training + inference. Overall, the best performing CLIP + MCAN architecture is shown in Figure [8]. It is the one where we augmented the features of pre-trained CLIP’s image with the features of Faster RCNN and replaced the GLoVe + LSTM features with the pre-trained CLIP’s text encoder features.
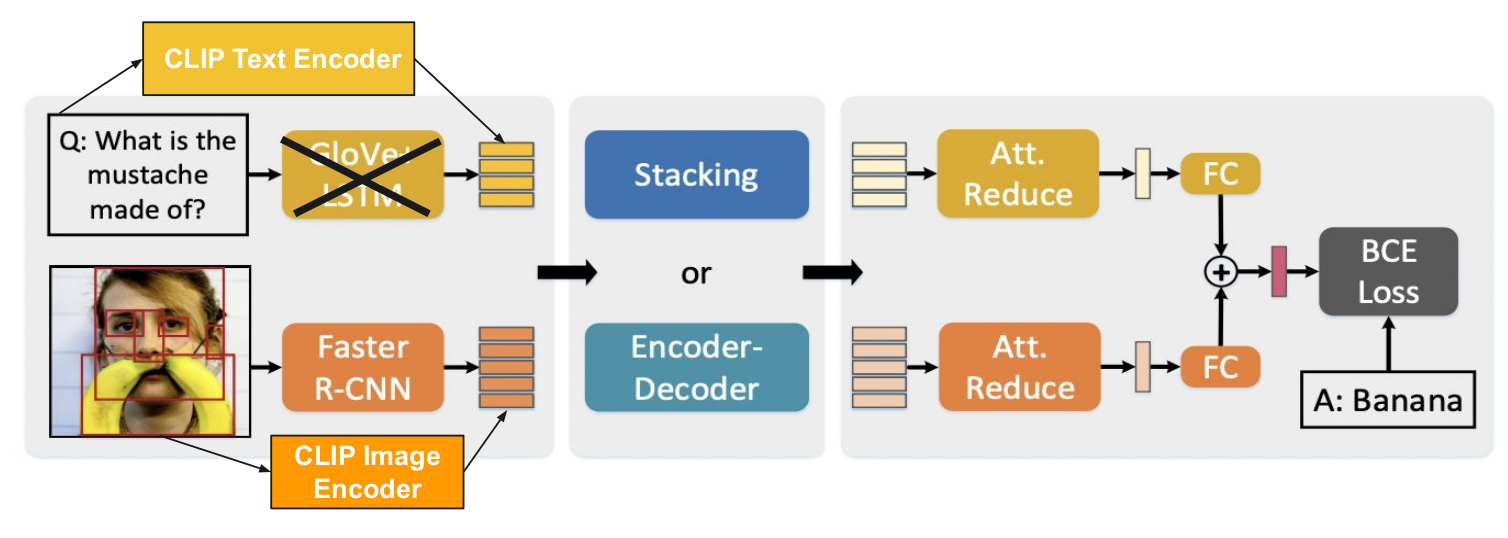
Fig 8. Best performing CLIP + MCAN Model.
LSeg + CLIP + VQA (Method 2)
We augmented the semantic features obtained from the image encoder of the pre-trained LSeg model with the combined image features in the CLIP + MCAN model. In this setting also, we performed direct inference and training + inference. The LSeg model requires input labels to generate the semantically segmented image. We used template matching techniques in order to obtain the keyword. Overall, the best performing LSeg + CLIP + MCAN architecture is shown in Figure [9].
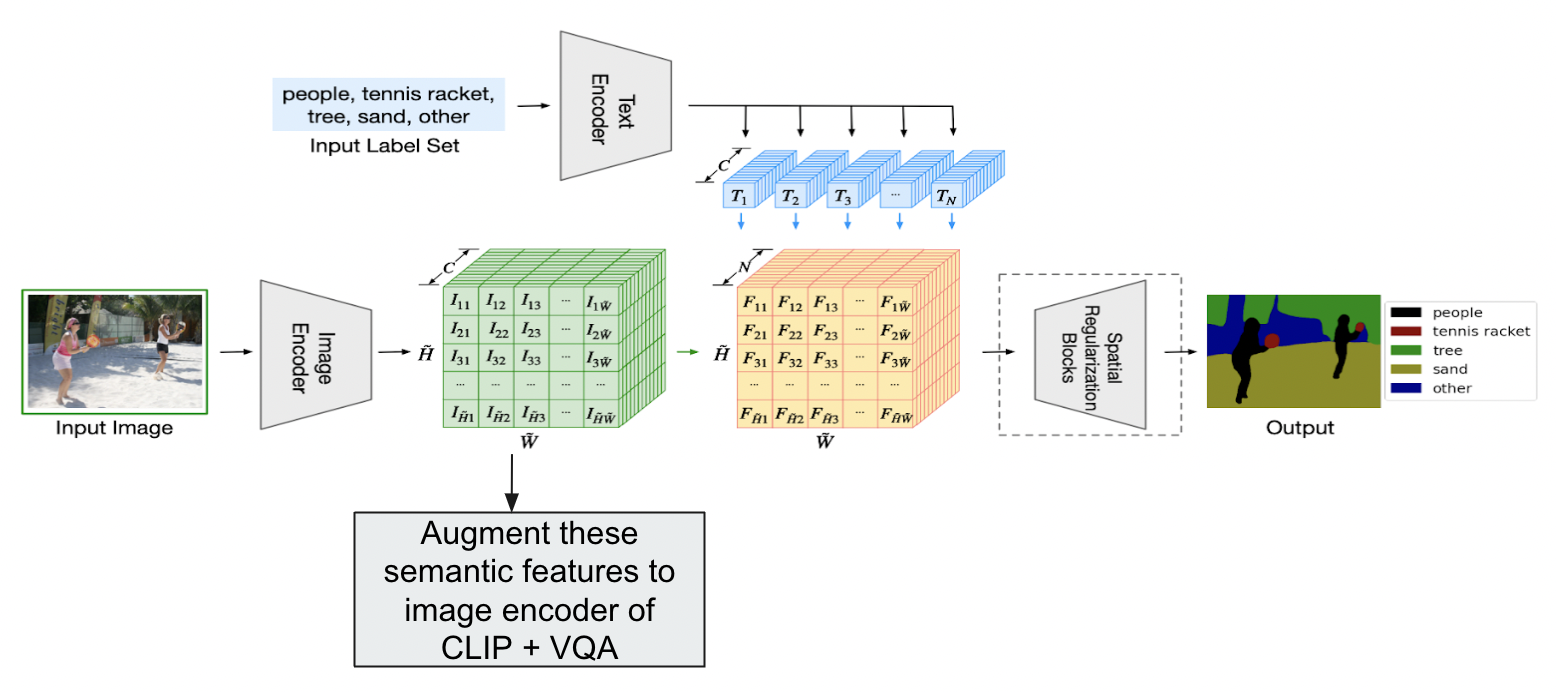
Fig 9. LSeg architecture augmented to MCAN VQA.
LSeg + Template Matching + Counting Objects for number based VQA (Method 3)
We focused particularly on improving the performance of number based VQA. We generated the keyword from the question using template matching i.e. looked for the phrase “how many” and then took out the first noun or plural noun present after that phrase. And then, we segmented the image semantically using a pre-trained Lseg model with the extracted keyword as its input label. Finally, we used some image processing techniques like dilation to enhance the shape of the segmented objects, followed by finding contours to count the number of segments.
M-CLIP + MCAN on Multilingual VQA (Method 4)
Following similar apporach to Method 1 we use the same apporach of augmenting the image encoder of MCAN with CLIP Image Encoder features and replacing the text encoder of MCAN with M-CLIP text encoder for the Multilingual VQA task. We use the baseline model as the model given here which is a CLIP Vision Encoder + BERT model.
Experiments and Results
The results obtained on various combinations of LSeg, CLIP and MCAN VQA are shown in the Figure [10]. We experimented with various combinations of image encoders (Faster RCNNs, CLIP image encoder with ResNet-50 backbone) and text encoders (GLoVe + LSTM, transformer-based CLIP text encoder). We have performed the experiments with only inference and then with training + inference in order to study the zero-shot capabilities of CLIP and LSeg models. As per the results obtained, the number-based VQA category gave the worst performance. So, we used the extracted keyword using template matching and fed that as input to LSeg and used image processing techniques to count the number of objects. We achieved a low test accuracy of 26.4% with this setting. Some of the qualitative results obtained with this model are shown in Figures [11], [12] and [13].

Fig 10. Results of CLIP + MCAN models with different encoders and training procedures.

Fig 11. Q: How many keyboards are there? Keyword: keyboards
Correct Answer: 2, Prediction: 1

Fig 12. Q: How many people are in this image? Keyword: people
Correct Answer: 1, Prediction: 1

Fig 13. Q: How many animals are there? Keyword: animals
Correct Answer: 3, Prediction: 3
The results obtained on Multilingual VQA by our methods are in shown Figure [14]. We present results on just the baseline model and our model (MCAN + M-CLIP) and also we ignore the answer type accuracies provided in earlier sections due to implementation of MVQA.

Fig 14. Results of M-CLIP + MCAN models on Multilingual VQA.
Observations
Only performing inference on the pretrained MCAN with pre-trained CLIP’s image and text encoders did not improve performance. This implies that pre-trained CLIP’s image encoder failed to show zero-shot capabilities on complex tasks like VQA. Replacing the Faster RCNN in MCAN completely with CLIP’s image encoder performed very badly. Augmenting the Faster RCNN features in MCAN with the CLIP image encoder’s features improved performance by ~1%. Replacing GLoVe + LSTM embeddings with CLIP text encoder’s features improved performance further. Here inference alone also gave good performance which implies that unlike the image encoder of pre-trained CLIP, its text encoder consistently showed zero-shot capabilities. Performing training + inference on this setting further improved the performance by ~1.5%. Semantic features obtained using LSeg further improved the performance by ~0.5%.
We also observe that both MCAN and CLIP + MCAN perform poorly on number based questions (VQA Models in General). LSeg + Template Matching + Counting Objects also performed poorly (accuracy = 26.4%). However, this is still much better than random guessing. The reason for the poor performance is because template matching was done by matching the phrase “how many” and only 85% of the questions contained that phrase. Moreover, template matching is not a very accurate method for extracting the keyword from number based questions. Also, the semantic segments obtained using LSeg sometimes clubbed the objects together if they are close by each other as shown in Figure. However, this worked well with images having single objects or multiple objects that are far enough from each other. We believe language-driven instance segmentation can help achieve much better results in this regard, effectively boosting the performance of current SoTA VQA models in Number based questions.
For the MVQA task, we observe that MCAN + M-CLIP model performs slightly worse than CLIP + BERT model which is the baseline from the MVQA repository when we just perform inference. This slight decrease could be due to challenging nature of MVQA task. We also believe training our model might have helped perform better on the MVQA task and might have even surpassed the baseline model which is already trained on the dataset. We were not able to perform training due to challenges as discussed later. Hence, this shows that M-CLIP is a good zero-shot learner at par performance with baseline on just inference.
Challenges and Limitations
In order to see if the observations we obtained on MCAN can be generalized to other other popular VQA models like Pythia [7], we could not perform the same experiments due to constraints on resources. We could also not perform an ablation study on various CLIP image and text encoders due to the high training times and complexity of other CLIP Image Encoders on the VQA 2.0 dataset.
The LSeg model is not useful for yes/no based questions. This is because of the limitation of the LSeg model to handle the scenario where labels that are not present in the image are given as input. The LSeg model assigns the pixels that have the highest probability of belonging to that label even though that label is not present in the image. This is the same reason why the LSeg model failed on number based questions with answer 0. Moreover, the LSeg model merged the nearby segments of objects into a single object and hence lost the count of objects in some instances. Language-driven instance segmentation might be more useful instead of language-driven instance segmentation. The template matching technique also is not feasible on 15% of the number based questions as they do not have the template that we were trying to match.
We were also not able to train M-CLIP + MCAN model the MVQA dataset due to the resource constraints as discussed above. Hence, we were only able to obtain inference scores of our model.
Future work
Leveraging language-driven instance segmentation instead of language-driven semantic segmentation seems to be more helpful for the VQA task. It is because nearby objects are being merged in the semantic maps obtained using semantic segmentation. Also, this can overcome the limitations of the LSeg model to incorrectly assign image pixel probabilities to class labels not present in the image. Future work in this direction could potentially give better results. Prompt engineering is another interesting area of research which could also benefit the VQA task. Generating various kinds of prompts by combining the question and answer and passing them as a single prompt to the text area might also lead to improvement in the performance of the VQA task. Template matching does not seem to have worked well for keyword extraction. Using better techniques instead of this would help in achieving better results. We can also work on further improving the segment counting methods used for answering the number based questions. Doing ablation studies on various CLIP image encoders can lead to better results than we achieved currently. We used a CLIP image encoder with ResNet50 backbone; however ResNeXt-101, Res50X4 and Visual Transformer based CLIP image encoder’s gave a better performance on other multimodal tasks. Also, training the MCAN + M-CLIP on the Multilingual VQA dataset is a good prospect for further improvement.
Conclusion
Leveraging CLIP’s image and text encoders for VQA improved the performance of MCAN VQA by ~2.5%. LSeg + CLIP + MCAN has further improved the performance by ~0.5%. The original MCAN did not perform well on Number based VQA questions. Even our proposed approaches, CLIP + MCAN and LSeg + Keyword Extraction + Counting Clusters, did not perform well on Number based VQA. However, using language driven instance segmentation could potentially lead to better performance. The CLIP’s image encoder failed to show zero-shot capabilities on the VQA task. However, the CLIP’s text encoder and the LSeg model gave good results on direct inference, conveying that they exhibit good zero-shot capabilities on a complex multimodal task like VQA. Similary, M-CLIP + MCAN display good zero-shot capabilites on the MVQA task. Since this task is very challenging, we believe that more creative approaches using the zero-shot capabilities of CLIP based models can vastly improve performance, especially in number-based questions.
Code repository
All of our codes are hosted in the GitHub Repo here
References
[1] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark,. “Learning transferable visual models from natural language supervision.” arXiv preprint arXiv:2103.00020., et al. 2021.
[2] Yash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Batra, and Devi Parikh. 2017. “Making the v in vqa matter: Elevating the role of image understanding in visual question answering.” In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 6904–6913.
[3] Hao Tan and Mohit Bansal. 2019. “Lxmert: Learning cross-modality encoder representations from transformers.” arXiv preprint arXiv:1908.07490., [cs.CL] 3 Dec 2019
[4] Zhou Yu, Jun Yu, Yuhao Cui, Dacheng Tao, and Qi Tian. 2019. “Deep modular co-attention networks for visual question answering.” In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6281–6290.
[5] Yu Jiang, Vivek Natarajan, Xinlei Chen, Marcus Rohrbach, Dhruv Batra, and Devi Parikh. 2018. “Pythia v0. 1: the winning entry to the vqa challenge 2018.” arXiv preprint arXiv:1807.09956., cs.CV] 27 Jul 2018
[6] Pham, VQ., Mishima, N., Nakasu, T. “Improving Visual Question Answering by Semantic Segmentation.” In: Farkaš, I., Masulli, P., Otte, S., Wermter, S. (eds) Artificial Neural Networks and Machine Learning – ICANN 2021. ICANN 2021. Lecture Notes in Computer Science(), vol 12893. Springer, Cham. https://doi.org/10.1007/978-3-030-86365-4_37, 2021.
[7] Li, Boyi, Kilian Q. Weinberger, Serge Belongie, Vladlen Koltun, and René Ranftl. “Language-driven Semantic Segmentation.” arXiv preprint arXiv:2201.03546 (2022).
[8] Antol, Stanislaw, Aishwarya Agrawal, Jiasen Lu, Margaret Mitchell, Dhruv Batra, C. Lawrence Zitnick, and Devi Parikh. “Vqa: Visual question answering.” In Proceedings of the IEEE international conference on computer vision, pp. 2425-2433. 2015.
[9] Gan, Chuang, Yandong Li, Haoxiang Li, Chen Sun, and Boqing Gong. “Vqs: Linking segmentations to questions and answers for supervised attention in vqa and question-focused semantic segmentation.” In Proceedings of the IEEE international conference on computer vision, pp. 1811-1820. 2017.
[10] Dosovitskiy, Alexey, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani et al. “An image is worth 16x16 words: Transformers for image recognition at scale.” arXiv preprint arXiv:2010.11929 (2020).
[11] Vaswani, Ashish, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. “Attention is all you need.” Advances in neural information processing systems 30 (2017).
[12] Devlin, Jacob, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. “Bert: Pre-training of deep bidirectional transformers for language understanding.” arXiv preprint arXiv:1810.04805 (2018).
[13] Singh, Amanpreet, Vedanuj Goswami, Vivek Natarajan, Yu Jiang, Xinlei Chen, Meet Shah, Marcus Rohrbach, Dhruv Batra, and Devi Parikh. “Mmf: A multimodal framework for vision and language research.” (2020).
[14] Anderson, Peter, Xiaodong He, Chris Buehler, Damien Teney, Mark Johnson, Stephen Gould, and Lei Zhang. “Bottom-up and top-down attention for image captioning and visual question answering.” In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 6077-6086. 2018.
[15] Li, Liunian Harold, Mark Yatskar, Da Yin, Cho-Jui Hsieh, and Kai-Wei Chang. “Visualbert: A simple and performant baseline for vision and language.” arXiv preprint arXiv:1908.03557 (2019).
[16] Krishna, Ranjay, Yuke Zhu, Oliver Groth, Justin Johnson, Kenji Hata, Joshua Kravitz, Stephanie Chen et al. “Visual genome: Connecting language and vision using crowdsourced dense image annotations.” International journal of computer vision 123, no. 1 (2017): 32-73.