MetaDrive: Compositional and Interactive Driving Scenarios with Human-in-the-Loop
In this project, we incorporated human interactions into the driving scenarios of MetaDrive platform, as a supplement to its compositionality, diversity, and flexibility. Experiments showed that human interactions could help improve RL agents’ responsiveness to traffic vehicles, obstacles, and accidents on the road.
Background
Nowadays reinforcement learning(RL) has extensive applications in the field of autonomous driving. To build RL sgents for autonomous driving, we usually perform training in simulators, as training in real-world settings can be expensive and impractical. This brings challenges for current simulation platforms: It need to capture the complexity and diveristy of real-world situations. Otherwise, RL agents trained in simulators may fail to generalize to unseen driving scenarios.
To address the generalization problem of RL algorithms in autonomous driving, some researchers proposed MetaDrive[1], a simulation platform including a wide range of driving scenarios with various road networks and traffic flows. Compositionality is the key feature of MetaDrive. A driving scenario is composed by four components: map, target vehicles, traffic flow, and obstacles. The map is further composed by a set of road blocks, which can be generated by procedural generation or imported from real-world data. The target vehicles are controlled by RL agents. The traffic flow contains a set of traffic vehicles responsive to the actions of target vehicles. The obstacles are randomly placed in scenarios, and collisions with obstacles could yield cost in RL training.
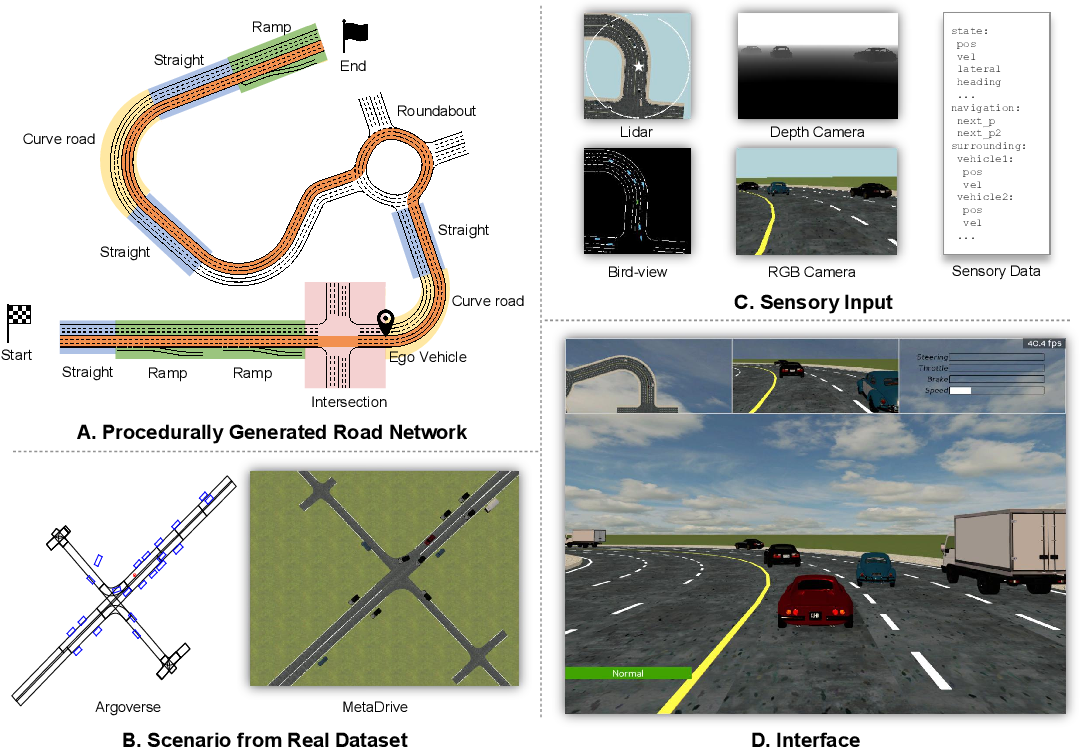
MetaDrive supports three kind of driving scenarios: For general single agent scenarios, the simulator composes a large number of diverse scenarios combining various road blocks and traffic vehicles; In safe exploraion scenarios, obstacles are randomly added on the road and a cost is yielded if a collision happens; Multi-agent scenarios usually include 20 to 40 agents and require collective motions.
MetaDrive largely facilitates the generalization of RL in autonomous driving. On the basis of its compositionality and flexibility, we hope to add interactivity as a new feature. Our goal is to further improve the efficiency and effectiveness of RL by including human in the loop. In our implementation, human could configure and adjust the driving scenarios in MetaDrive, thus increasing the complexity of driving scenarios and enhancing the performance of RL agents.
Motivation
Human interaction will help the performance of reinforcement learning and autonomous driving from many aspects: On the one hand, human could provide necessary guidance to RL agents during driving. On the other hand, human involvement could augment the complexity and diversity of driving scenarios, so that it could further facilitate the generalization ability of RL agents. Including human in the loop also makes the scenarios closer to the situations in real-world applications, where human collaborate with AI in driving tasks.
Implementations
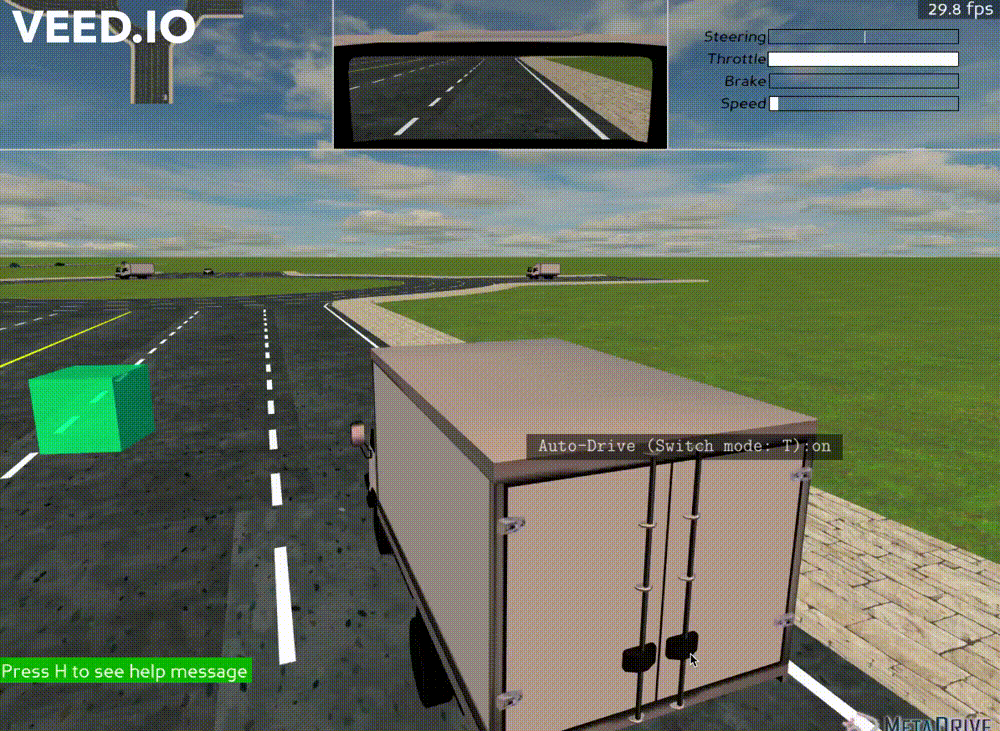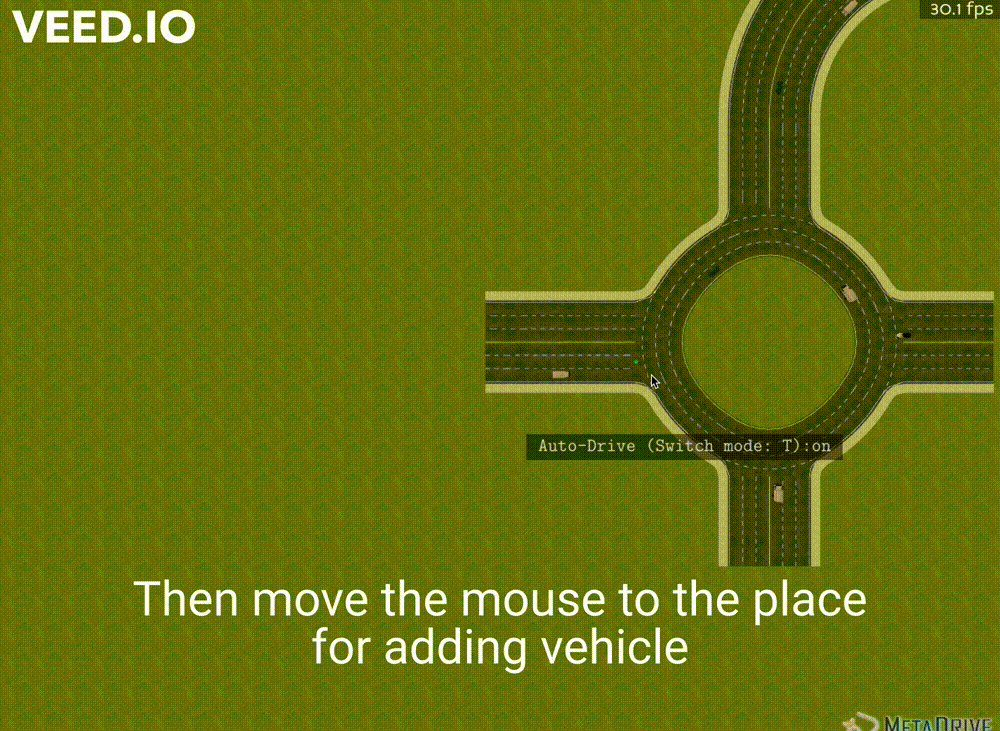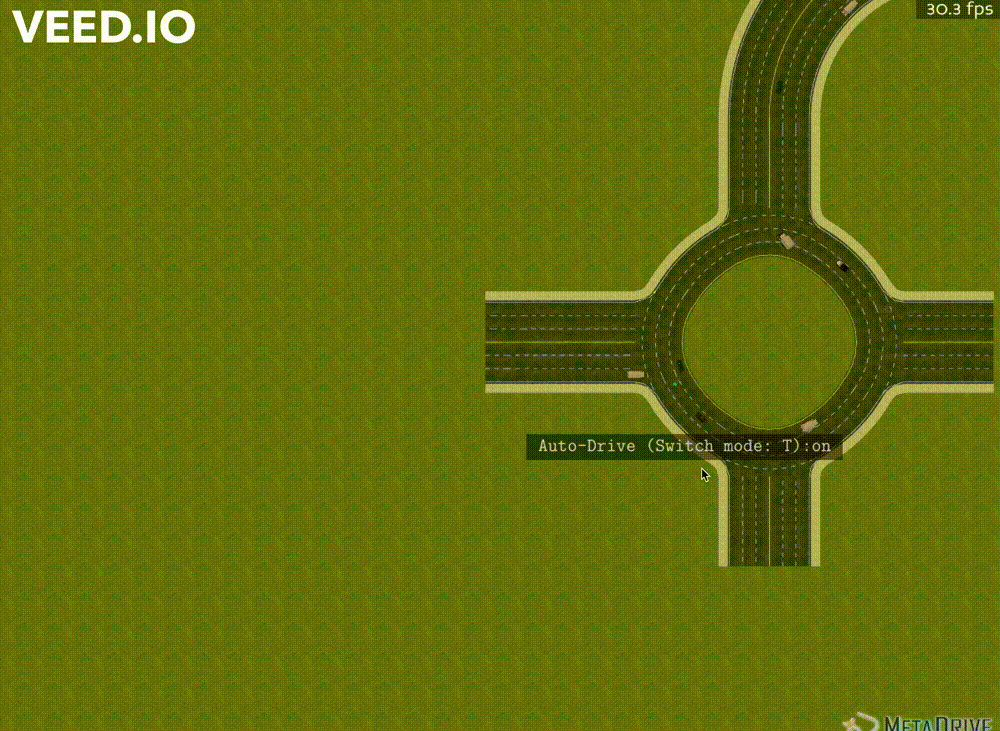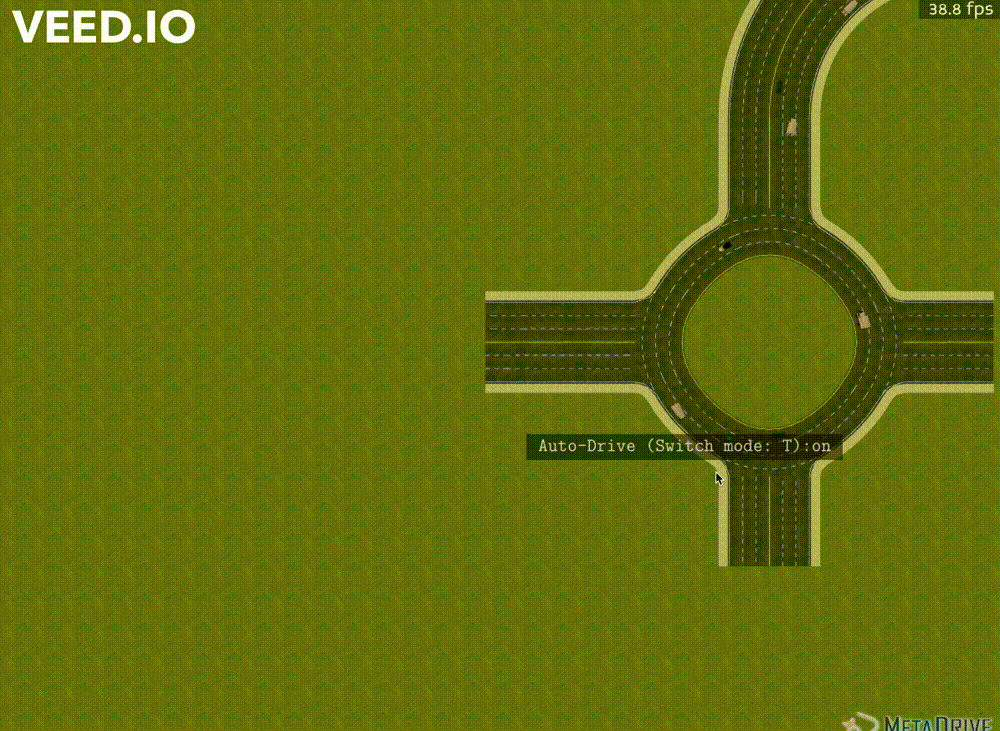
Our implementation essentially provides users with a way to add vehicles and change traffic flow density. See Figure 2 for a live demostration of our new feature. You could also visit here for a more clear video demonstration. Since our implementation is directly based on the Panda3D engine, the code can be also modified to more diverse implementations, such as using mouse to drag vehicles, deleting a selected vehicle, adding obstacles and so on. In this section, we will first introduce the logic flow simulation process of MetaDrive. Then we will go through our implementation details.
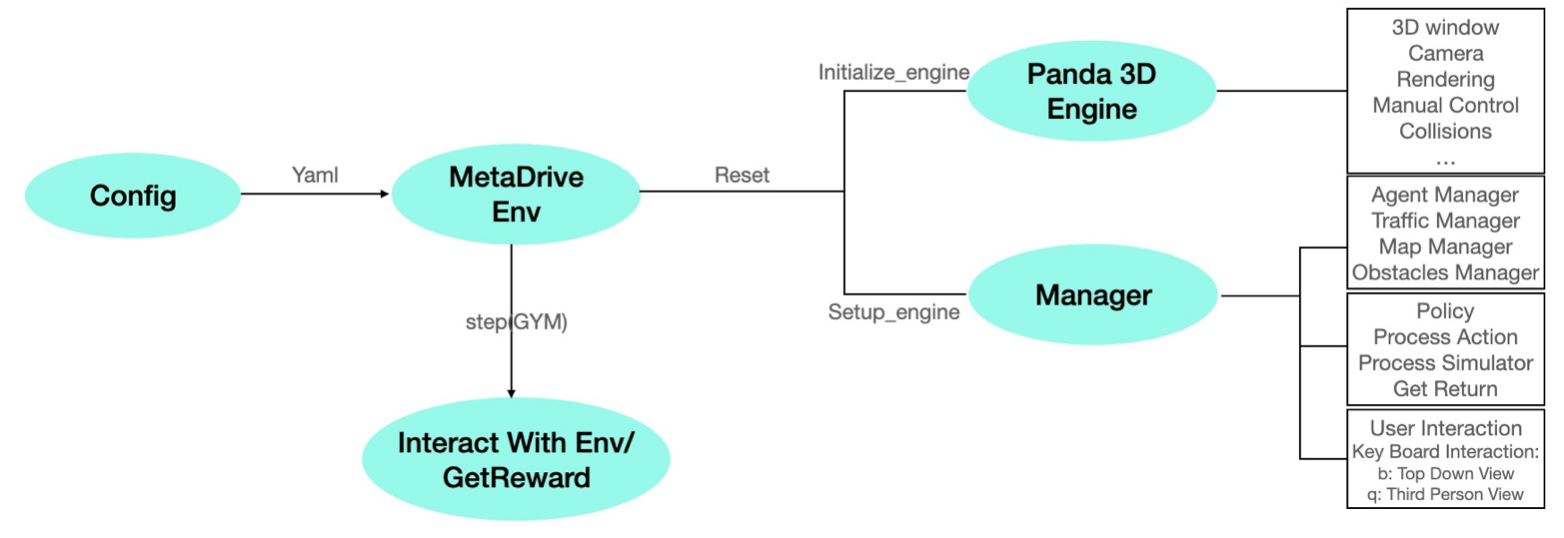
As shown in Figure 3, the MetaDrive simulation starts from a configuration file, where the user could specify the parameters to define the simulation scenarios. Common parameters include the traffic flow density, the number of road lines, agent policy, etc. The configuration file will set up the MetaDrive environment. When it set up the environment, it will first initialize the MetaDrive engine, which is based on the Panda3D. The initialization will handle the 3D windows and rendering that can be perceived by the human eye. It will also set up the collision handling mechanism which is useful to calculate the reward for the reinforcement algorithm. After it initializes the engine, then it will set up the manager to manage vehicles and policy. MetaDrive has different managers for traffics, ego vehicle, map, and obstacles. Ego vehicle and traffics are controlled by different managers because ego vehicles are generally controlled by reinforcement learning algorithms and traffic vehicles are controlled by rule-based algorithms. The MetaDrive also provides the policy for different use cases. During the simulation process, the policy will handle the action, for example, steering angle and engine force. Then the complex physical simulation process will be passed to the simulator to get the rewards. MetaDrive also implemented some user interactions. For example, it provides keyboard interaction, which could let the user enter different views.
Our implementation providing the mouse clicking interactions was based on the user interaction part. To add vehicles by the position of the mouse, our algorithm first found the corresponding lane and position. In details, we used the Panda3D Collision Ray to find the objects corresponding to the mouse position. This method would generate a ray that passes through the mouse position and find the road colliding with the ray. After finding the corresponding road, we used the Panda3D Bullet method to convert the mouse local position to the global physical world position in MetaDrive. With a specific position, we could then respawn a vehicle on that road. The respawn function would calculate the road longitude, take the road index as the input, and randomly generate a new vehicle. In the implementation, this generated vehicle will be set to random color, size, and policy. Our implementation supports users to add new vehicles at any position on the roads.
Experiments
Set-up
On the updated MetaDrive platform, we conducted a series of experiments that contrasted the performance of RL agents in driving scenarios with or without human interactions. In the experiments, we used such a form of human interaction: human participants add vehicles in front of the running target vehicle in an in-execution driving scenario. The target vehicle will respond to the added vehicle from two aspects:
-
Firstly, the target vehicle needs to avoid crashing to the added vehicle. It may slow down, make a detour, or stop, to prevent collisions with added vehicles.
-
The target vehicle also needs to respond to the events caused by the added vehicle. For example, the added vehicle could crash to other traffic vehicles or obstacles on the road.
By incorporating above interactions, we hope to augment RL agents’ judgement and reaction capability to traffic, obstacles, and possible accidents on the road, thus improving their performances in autonomous driving tasks. To examine this, we runned the pre-trained RL algorithms on two kinds of scenarios in MetaDrive: general single agent scenarios and safe exploration scenarios. Our expectation was that for both scenarios, the performance of RL with human interactions would be better than the performance without human interactions.
The metrics for RL performance are the cumulative reward and cost in a driving scenario. In MetaDrive, rewards are generated when the target vehicle moves forward, drives faster, or reaches the destination. Cost is usually used to measure the safety during driving. It can be yielded when the target vehicle crashes to other objects or drives out of the road.
Results
We compared RL performance with or without human interactions in single agent and safe exploration scenarios. The comparison results are summarized in Table 1. Besides, we also plotted RL performances as a function of the number of vehicles added in the scenario. For each comparison, we not only described the difference, but also conducted hypothesis testing to examine whether the difference was statistically significant. Our analysis used a significance level of 0.05.

Single Agent Comparison
We separately runned 80 single agent scenarios without human interactions and 80 single agent scenarios with human interactions. As indicated in Table 1, RL agents achieved more rewards and less costs when human interactions were incorporated. We further conducted a t-test to compare the performance: For cumulative reward, there was a nearly significant difference between RL agents with and without human interactions(t = -1.906, p = 0.058). For cumulative cost, the difference between the two groups was not statistically significant(t = 1.101, p = 0.273), but there was an observable tendency in the data that RL agents with human interactions showed less costs. It seems incorporating human interactions could strengthen the RL agent’s responsiveness to unexpected traffic and possible accidents, so that the performance of single agent scenario was improved.
Number of Interactions
On the basis of above comparison, we further plotted RL performance as a function of the number of added vehicles. As shown in Figure 4, the cumulative reward firstly increased as the number of added vehicles incremented. However, when the number of added vehicled exceeded 4, there was a sharp drop of reward. Figure 5 shows a similar change of performance on cumulative cost. When the number of added vehicles reached 5, the cumulative cost generated in a scenario increased sharply.
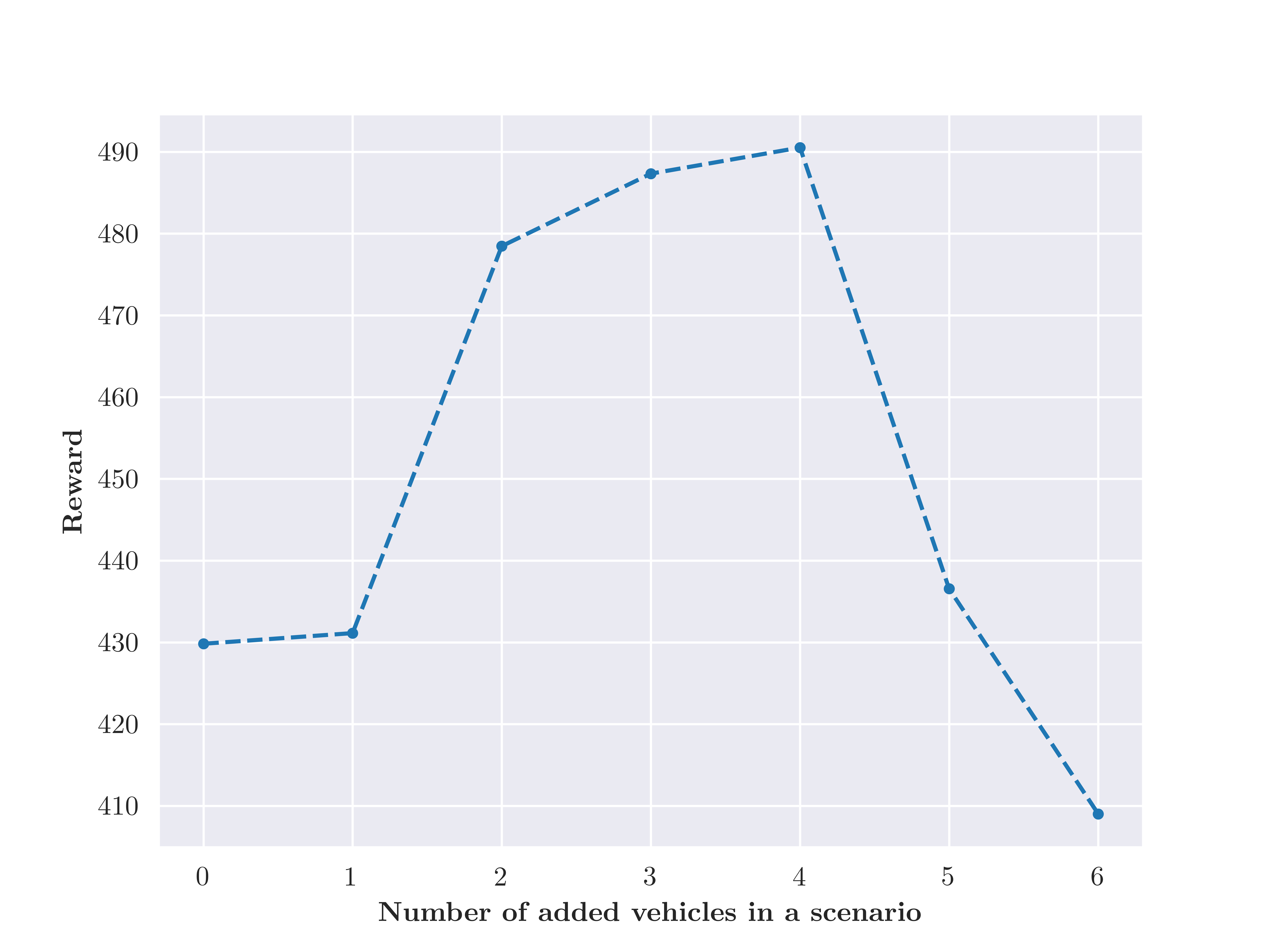
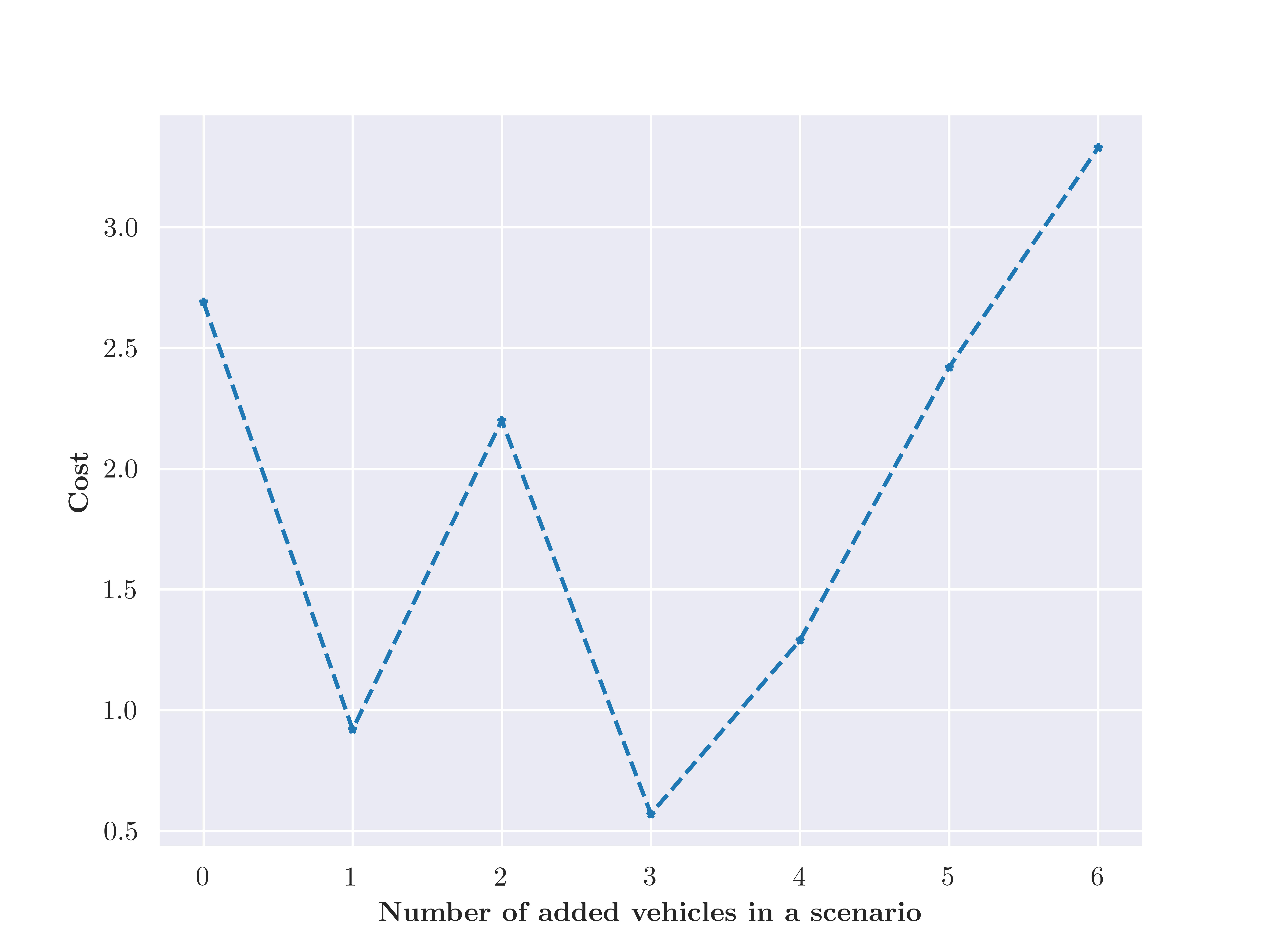
Statistical analysis was further conducted on the data grouped by number of added vehicles. Analysis of Variance did not show a significant difference in the reward(F = 0.922, p = 0.340) and cost(F = 1.941, p = 0.197) among different number of added vehicles. However, Posthoc Pairwise Comprison indicated there was a significant difference in the reward between adding 4 vehicles and adding 6 vehicles(p = 0.045). There was also a significant difference in the cost between adding 3 vehicles and adding 6 vehicles(p = 0.015). From Figure 4, Figure 5, and the analysis, we could see that it is helpful to have some interactions with RL agents during driving, but too many interactions may serve as a kind of interruption, negatively influencing RL performance.
Safe Exploration
Furthermore, we tested the RL agents with or without human interactions separately on 30 safe evaluation scenarios. As shown in Table 1, there are more rewards and less costs for scenarios incorporated with human interactions. T-test results indicated that the difference in reward was not significant(t = -1.714, p = 0.098), but the difference in cost between the two groups of data was proven to be statistically significant(t = 2.622, p = 0.019). It seems that adding vehicles could enhance RL agents’ reaction ability to other objects in the scenario, including traffic vehicles and obstacles on the road. We also observed in the experiment that the added vehicle could crash to the obstacles in front of the target vehicle, which helped the target vehicle identify possible obstacles and make a detour in time, thus reducing the cost generated in scenarios. In this situation, the added vehicle served as a “pioneer” that explored the road for the target vehicle.
Conclusion and Discussion
In this work, we enriched the MetaDrive platform with interactivity and enabled a new feature of adding vehicles in running scenarios. Our experiments showed human interactions, if controlled within an appropriate amount, could help improve RL agents’s resposiveness to traffic, obstacles, and accidents.
Future work needs to explore more helpful interactions on more complex scenarios. For example, the form of interations could be changed to adding obstacles, changing the direction of traffic vehicles, modifying the road blocks in a scenario, and so on. It is also interesting and challenging to extend these human interactions to more complicated driving scenarios, such as multi-agent scenarios. By comprehensive experiments, we believe a clear understanding of human interactions’ role in reinforcement learning and autonomous driving can be achieved. In the future, there will be effective, fit-for-purpose, and easy-to-operate interactions applied in relevant settings.
Reference
[1] Li Q, Peng Z, Xue Z, Zhang Q & Zhou B. (2021). Metadrive: Composing diverse driving scenarios for generalizable reinforcement learning. arXiv preprint arXiv:2109.12674.