Module 2: Human-AI Creation - Text to Image Generation
Text to image generation has been famous in recent times with the advancements in the generative models like GANs, Autoregressive models, Diffusion based models, etc. There have been exciting papers on text to image generation using these concepts. One such paper is Imagen (7) that has been recently released by Google research. In this work we aim to provide a survey of methods used to achieve the text to image generation task comparing them both qualitatively and quantitatively.
- Introduction
- GAN based models
- Autoregressive models
- Diffusion based models
- Qualitative Comparison of models
- Quantitative Comparison of models
- Limitations and Risks
- Conclusion
- Reference
Introduction
There have many works that tried to achieve the task of text to image generation. Few works like Imagen(7), DALLE(5) have tried to obtain the images from plain text. Few works tried to use additional information such as segmentation maps like Make-a-scene (2). The research of the image generation started with RNN based models where the pixels were generated sequentially and attention was also used to create better images like in DRAW (3). There have been multiple GAN based approaches for the text to image generation task. Some examples include DM-GAN (10) that introduced a dynamic memory component, DF-GAN (8) that fused text information into image features, XMC-GAN (9) that used contrastive learning to maximize the mutual information between image and text. There were few au- toregressive models that were devised to perform this task like DALL-E (6), CogView (1) and Make-a-scene (2) that train on text and image tokens. Finally there are diffusion based models that are very good at generating photorealistic images. Diffusion based models are being used in state of the art methods like GLIDE (4), DALL-E 2 (5) and Imagen. We explain a few models in each of the above different methods using GANs, Autoregressive models, and Diffu- sion based models. We also provide qualitative comparisons among the various models mentioned above to give the reader a better understanding of the improvements in the latest state-of-the art methods compared to previous methods.
GAN based models
XMC-GAN
The images generated by XMC-GAN are coherent, clear, photo-realistic scenes and have high semantic fidelity. The XMC-GAN is a conditional GAN based method maximizes the mutual information between image and text via multiple contrastive losses that capture inter-modality and intra-modality correspondences. It uses an attentional self-modulation generator, which enforces strong text-image correspondence, and a contrastive discriminator, which acts as a critic as well as a feature encoder for contrastive learning. It comprises of a one-stage generator made of self-modulation layer that generates image at the desired resolution. In the contrastive discriminator block, the original image feature is fed through two more down-sampling blocks and a global pooling layer. Finally, a projection head computes the logit for the adversarial loss, and a separate projection head computes image features for the image-sentence and image-image contrastive loss. The three losses that are minimized are: image-text contrastive loss, contrastive loss between fake and real images with shared description and contrastive loss between image regions and words. XMC-GAN generated higher quality images that better match their input descriptions, including for long, detailed narratives when compared to the other GAN based approaches. it outperformed the previous models in terms of both realism and text-image alignment while being a simple one stage model. The architecture of XMC-GAN is shown in Figure 1
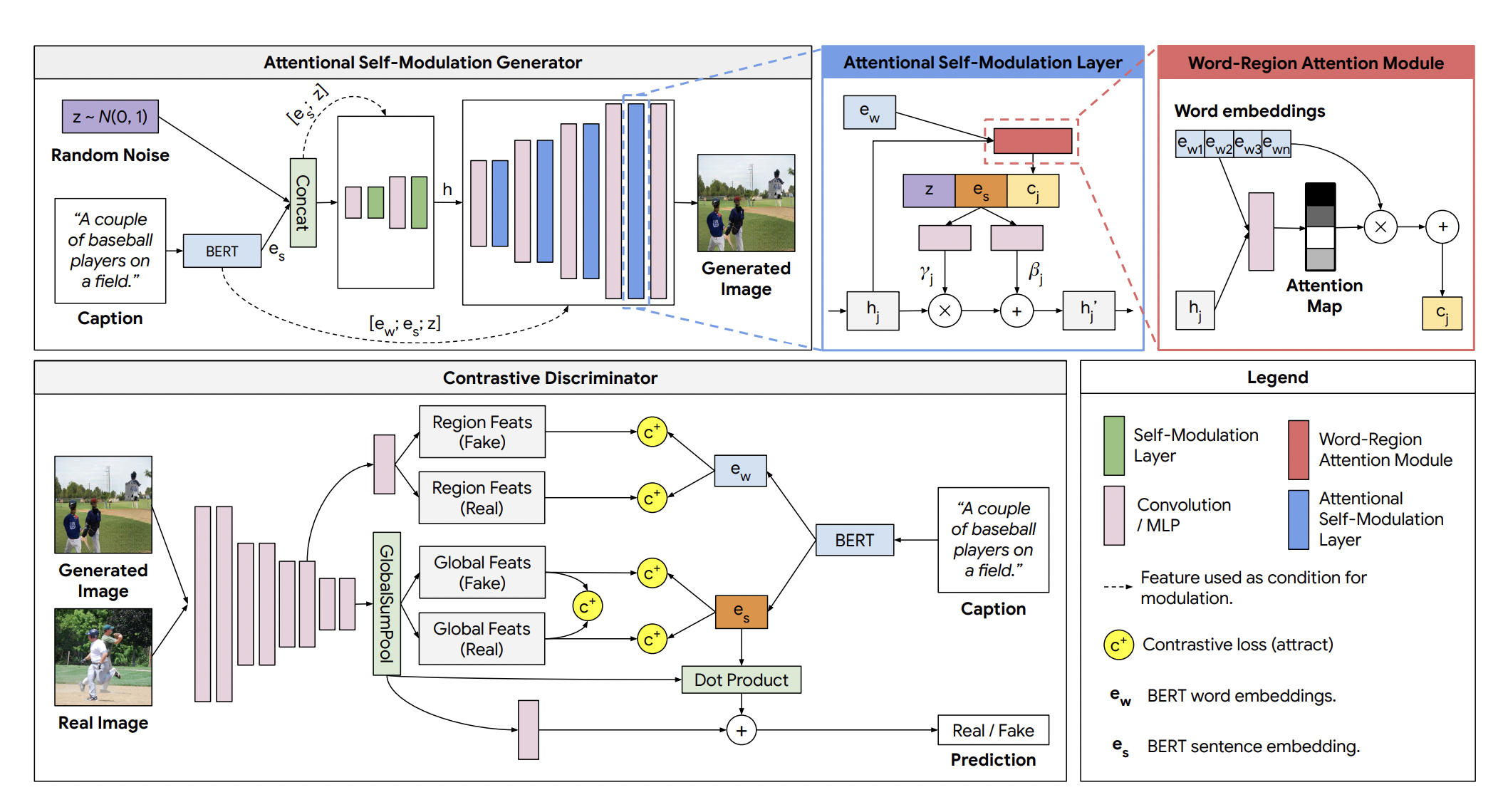
Fig 1. XMC-GAN Architecture
Autoregressive models
DALLE
DALLE is a zero shot autoregressive model that has been trained on images from web and tested on MS COCO dataset and has showed very good results. They create an autoregressive model that used both image and text tokens to train the model. The image tokens are generated through a discrete VAE instead of using pixels directly to reduce the number of parameters in the model as the number of pixels could be huge. This reduced the number of parameters by 192 times. They also append the 256 BPE text tokens with 1024 image tokens to train the model to learn the joint distribution of both image and text tokens.
Make-a-scene
Make-a-scene is a state of the art model in the autoregressive models for text to image generation. This model uses additional information in the form of segmentation images along with text information. The segmentation information given by user is optional and even if given, the segmentation information might be ignored as it is not explicitly tied to the loss function. The model takes text as input and generates text tokens, then using an optional segmentation map, scene tokens are generated. If the segmentation map is not given, the model generates the scene tokens from text. During the training process image tokens are generated from the Vector quantized encoder. The autoregressive model is trained using all these tokens to learn the parameters. During inference time, the model takes the text and optional segmentation map as input and generates image tokens in the vector quantized space that are then decoded into high quality images using a decoder. The main improvements in Make-a-scene compared to existing methods is to use specific losses in terms of face-awareness and object-awareness adhering to human emphasis in token space. They also use transformer classifier free guidance to improve the quality of images. We mention more details about classifier free guidance in the Diffusion section.
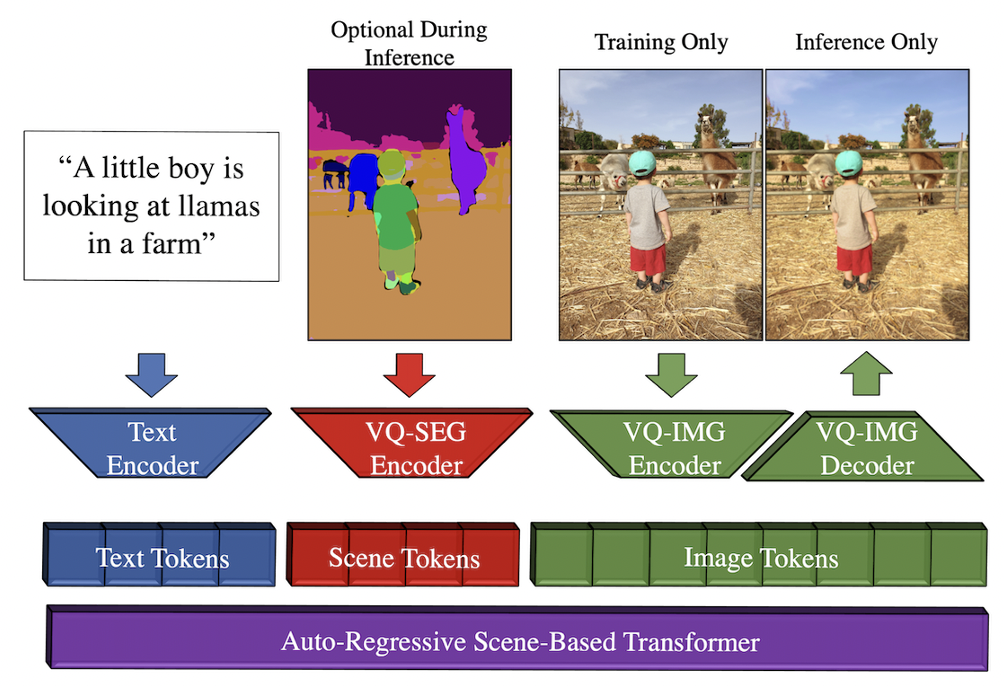
Fig 2. Make-A-Scene Architecture
Diffusion based models
GLIDE
GLIDE is one of the first diffusion based models to perform the task of text to image generation. They employ various methods to guide the diffusion model to generate images of very high quality. One such method is to use a guidance based on CLIP model. Here the diffusion model is additively perturbed by the log probability of a target class predicted by the classifier. The second way is to use Classifier free guidance where it is not dependent on any model for guidance. They have observed that Classifier free guidance based images have had better human preference for the images due to their superior quality. The approach used in GLIDE are further referenced and improved in the folllowing models.
DALL.E 2
DALL·E 2 creates original, realistic images and art from a text description by combining concepts, attributes, and styles. Apart from that, it allows making realistic edits to existing images from text captions. It also allows adding and removing elements from an image while taking shadows, reflections and textures into account. It can also create different variations in an image. It is a two-stage model. In First stage, a CLIP text embedding of a given text caption is fed to an auto-regressive or diffusion prior that generates an image embedding. Second stage is a diffusion model based decoder that generates an image conditioned on the image embedding. CLIP embeddings are concatenated to the GLIDE text encoder’s embeddings. Decoder leverages classifier-free guidance which improves fidelity at the cost of sample diversity. The joint-embedding space in CLIP helps this model in achieving good zero shot capability. The diffusion decoder invert’s the CLIP’s image encoder and hence this model is called unCLIP. The inverter is non-deterministic and hence can produce multiple output images for an image embedding. The architecture of DALL.E 2 is shown in Figure 3
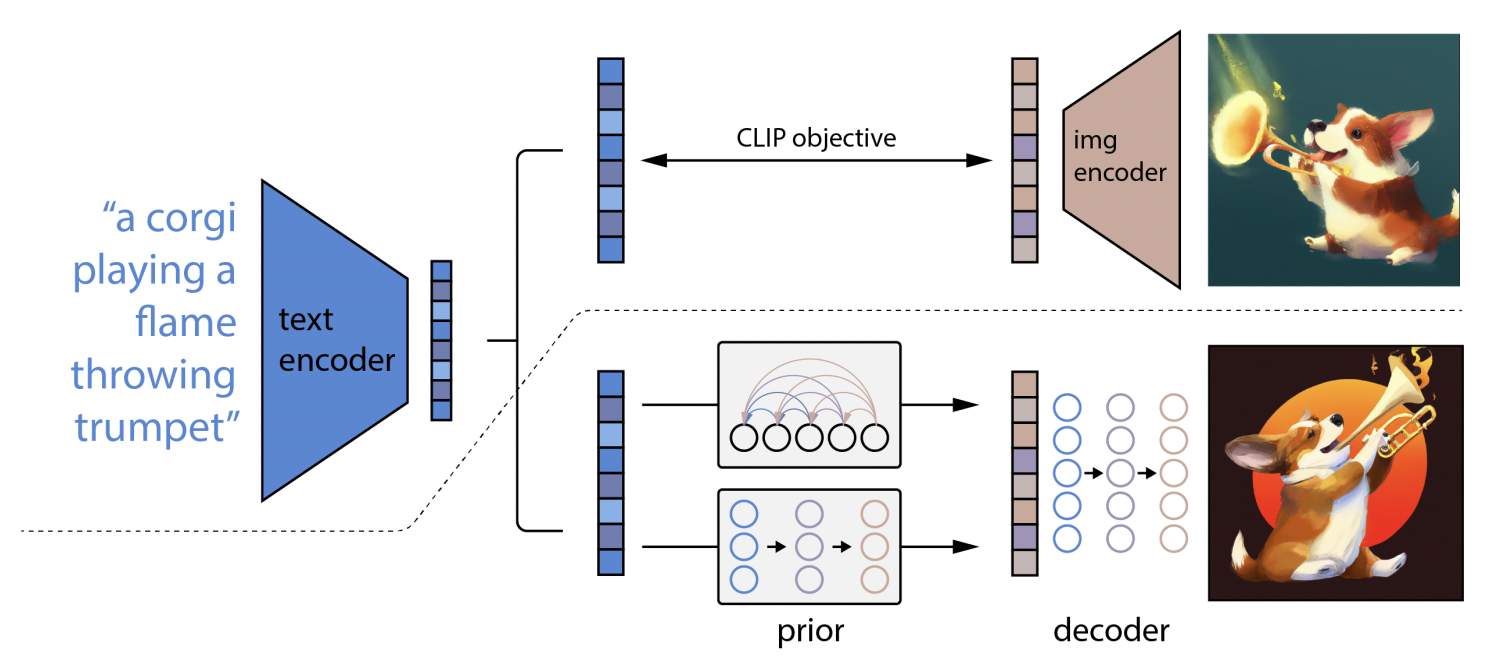
Fig 3. DALL.E 2 Architecture
Imagen
Imagen has shown unprecedented degree of photorealism and a very deep level of language understanding. It uses a large frozen T5-XXL encoder (that is pre-trained on text-only coropora) to map input text into a sequence of em- beddings and a 64×64 image diffusion model, followed by two super-resolution diffusion models for generating 256×256 and 1024×1024 images. The diffusion model incorporates an Efficient U-Net architecture which is much simpler, converges faster and memory efficient. A new diffusion technique called dynamic thresholding that leverages high guidance weights aided in the generation of images that are more photorealistic and detailed than previously possible. It has outperformed all other models on DrawBench, a new comprehensive and challenging evaluation benchmark for the text-to-image task which comprises of text prompts designed to probe different semantic properties of models. The architecture of Imagen is shown in Figure 4
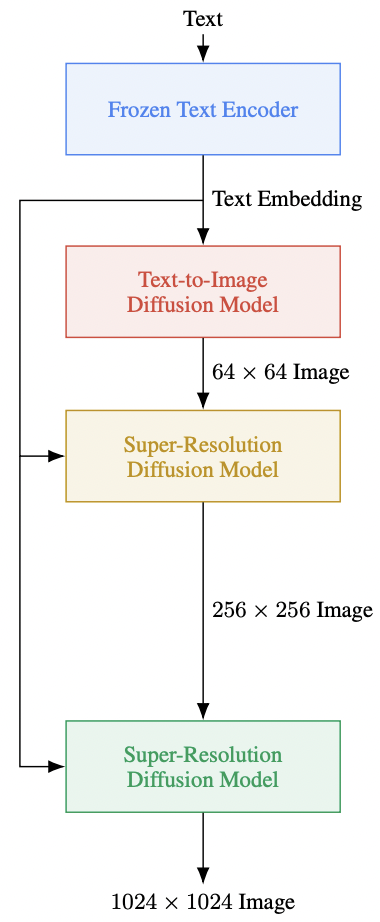 Fig 4. Imagen Architecture
Fig 4. Imagen Architecture
Qualitative Comparison of models
Imagen vs DALL.E 2
DALLE 2 was the state of the art model before Imagen was released a few days ago. The main difference between DALLE 2 and Imagen is that DALLE 2 uses the CLIP based image representation generated as the intermediate representation and then uses diffusion models to create images and also to further improve the quality of images. Imagen however states that use of language model based word embeddings provide better semantic meaning to the images generated. These word representations are used as the intermediate layer and then diffusion models are used similar to DALLE 2. This proves that language model based word embeddings learn better semantic meanings due to the huge amount of corpus on which the language model is trained. Although embeddings generated through text-image pair learning such as CLIP has very good quality like demonstrated in DALLE 2, they could not match the performance of the language model based embeddings used in Imagen.
Diffusion based models vs other models
We have seen in recent publications from Imagen and DALL.E 2 that diffusion based models have better performance compared to GANs and autoregressive models. While it is proven that diffusion based models create better photorealistic images compared to other methods, it is yet to be seen if these models have the best possible semantic meaning transfer from text to image compared to other models. As we have seen the results of Make-a-scene paper, they have outperformed the then existing diffusion based models like GLIDE using additional information such as segmentation maps. Hence it is pretty interesting to further wait for these different types of models outperform each other in the image generation tasks.
General comparison
Imagen, DALL.E 2, GLIDE and DALL.E 1 showed zero-shot capabilities on COCO dataset. Quatitative comparison of Imagen and DALL.E is shown in Figure 5. The results show that DALL.E 2 struggles on prompts where it has to bind two separate objects to two separate attributes (colors). Figure 8 shows that GLIDE fails to handle prompts with quoted text. However, GLIDE produced much more realistic images in zero-shot fashion over previous state-of-the-art models as shown in Figure 9. DALL.E 1 performed better than it’s prior work based on GANs. It achieved high quality image generation on COCO zero-shot as shown in Figure 10. The guidance has improved aesthetic quality of the images produced by both GLIDE and DALL.E 2. In addition to text-to-image generation, both GLIDE and DALL.E 2 also allow addition/removal of objects from images considering various factors and several variations of the output images can be generated. GLIDE can be used to transform simple line sketches into photorealistic images, and its zero-sample generation and repair capability for complex scenarios is strong. It can also produce the images in various styles such as style of a particular artist or a painting or generic styles like pixel art. In order to handle complex prompts, GLIDE provides editing capabilities, which allows humans to iteratively improve the samples until they match more complex prompts. GAN based and autoregressive models could not compete with the diffusion based models as they fail to recreate very complex scenes and accurately handle text descriptions containing multiple/complex objects. Most of them did not even show zero-shot capabilities. Amongst the GAN based approaches, XMC-GAN performed the best as shown in Figure 6. But it can still not handle complex prompts as shown in Figure 7

Fig 5. Imagen(left image) vs DALLE.2 (right image)

Fig 6. XMC GAN vs other GAN models

Fig 7. Original image(left image) vs XMC-GAN output image (right image)

Fig 8. Imagen (left 2 images) vs GLIDE (right 2 images)

Fig 9. GLIDE vs XMC-GAN, DALLE 1

Fig 10. Images from top to bottom : Validation, DALLE 1, DF-GAN, DM-GAN, ATTN-GAN
Quantitative Comparison of models
The FID scores of various models that were trained or directly tested zero-shot on COCO are shown in Table 1. Dif- fusion models performed the best in image generation, they outperformed GANs in terms of fidelity and diversity, without training instability and mode collapse issues. Imagen, DALL.E 2, GLIDE and DALL.E 1 were directly tested zero-shot on COCO. Imant work of DALL.E 2 and even other models that were trained on COCO. Human raters have also reported Imagen to be on-par with the reference images in terms of image-text alignment. Among the models trained on COCO, Make-A-Scene gave the best FID score. Compared to DALL.E 1, DALL·E 2 generated more realistic and accurate images with 4x greater resolution. DALL·E 2 was preferred over DALL·E 1 for its caption matching and photorealism when evaluators were asked to compare 1,000 image generations from each model. 71.7% preferred it for caption matching and 88.8% preferred it for photo-realism. Humans slightly preferred GLIDE compared to DALL.E 2 in terms of photorealism, but the gap is very small. Even with similar photorealism, DALL.E 2 was strongly preferred over GLIDE in terms of diversity, highlighting one of its benefits. GLIDE performed better than DALL.E 1 despite utilizing only one-third of the parameters. Human evaluators preferred GLIDE’s output images over DALL.E 1’s, even though it is a considerably smaller model (3.5 billion parameters) when compared to DALL.E 1 (12 billion parameters). When GLIDE was compared against DALL.E 1 by the human evaulators, GLIDE was chosen 87% of the time when evaluated for photorealism, and 69% of the time when evaluated for caption similarity. When DALL.E 1 was released, it outperformed the previous work that were based on GANs (AttnGAN, DM-GAN, DF-GAN, etc). When compared against DF-GAN, DALL.E 1 received the majority vote for better matching the caption 93% of the time and that for being more realistic 90% of the time. XMC-GAN was chosen by 77.3% for image quality and 74.1% for image-text alignment, compared to three GAN based models: CP-GAN, SD-GAN, OP-GAN.
Limitations and Risks
These image generation models could be used for malicious purposes, including harassment and misinformation spread, and can also raise many concerns regarding social and cultural exclusion and bias. Hence, the authors of state-of-the- at models like Imagen and DALL.E 2 have not made their code public. The authors of Imagen propose to explore a framework for responsible externalization that balances the value of external auditing with the risks of unrestricted open-access. Imagen encodes several social biases and stereo- types, including an overall bias towards generating images of people with lighter skin tones and a tendency for images portraying different professions to align with Western gender stereotypes. It also encodes a range of social and cultural biases when generating images of activities, events, and objects. The authors of DALL.E 2 have developed safety mitigations, they have limited the ability for DALL·E 2 to generate violent, hate, political or adult images as per their content policy. Currently, they are working with external experts and are previewing DALL·E 2 only to a limited number of trusted users. One of the previous works, GLIDE has also mentioned about similar limitations of the model and hence trained a smaller model with vetted images and also red teaming the model with a set of adversarial prompts to make the model safer compared to their full model. Hence they released GLIDE(filtered) which is a smaller version of the full model. This type of model creation can improve the research further ans also protect the model from generating images for malicious purposes.
Conclusion
This review presented an overview of state-of-the-art text-to-image synthesis methods and compared their performances on COCO dataset. Some of those models, especially the diffusion based models showed good zero-shot capabilities. We examined current evaluation techniques (text-image alignment, image quality, human evaluation), and discussed open challenges. We have also discussed about the limitations and the cases where certain models deviated from generating expected images. From the above survey, we conclude that text to image generation is an interesting task with very good advancements in the results from the time it has started. We can see a lot of improvement in the FID score of zero shot learning and the latest state-of-the-art models are able to handle even the complex prompts really well. Overall diffusion models seem to outperform other models due to their ability to create high quality photorealistic images. GAN and Autoregressive models are very good as well but are not performing better than diffusion based models in the zero-shot models. There has been relatively less work on social bias evaluation methods for text-to-image models and that is one potential area for future research.
Reference
[1] Ming Ding, Zhuoyi Yang, Wenyi Hong, Wendi Zheng, Chang Zhou, Da Yin, Junyang Lin, Xu Zou, Zhou Shao, Hongxia Yang, et al. Cogview: Mastering text- to-image generation via transformers. Advances in Neural Information Processing Systems, 34, 2021.
[2] Oran Gafni, Adam Polyak, Oron Ashual, Shelly Sheynin, Devi Parikh, and Yaniv Taigman. Make- a-scene: Scene-based text-to-image generation with human priors. arXiv preprint arXiv:2203.13131, 2022.
[3] Karol Gregor, Ivo Danihelka, Alex Graves, Danilo Rezende, and Daan Wierstra. Draw: A recurrent neu- ral network for image generation. In International Conference on Machine Learning, pages 1462–1471. PMLR, 2015.
[4] Alex Nichol, Prafulla Dhariwal, Aditya Ramesh, Pranav Shyam, Pamela Mishkin, Bob McGrew, Ilya Sutskever, and Mark Chen. Glide: Towards photore- alistic image generation and editing with text-guided diffusion models. arXiv preprint arXiv:2112.10741, 2021.
[5] Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text- conditional image generation with clip latents. arXiv preprint arXiv:2204.06125, 2022.
[6] Aditya Ramesh, Mikhail Pavlov, Gabriel Goh, Scott Gray, Chelsea Voss, Alec Radford, Mark Chen, and Ilya Sutskever. Zero-shot text-to-image generation. In International Conference on Machine Learning, pages 8821–8831. PMLR, 2021.
[7] Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily Denton, Seyed Kamyar Seyed Ghasemipour, Burcu Karagol Ayan, S Sara Mahdavi, Rapha Gontijo Lopes, et al. Photorealistic text-to- image diffusion models with deep language under- standing. arXiv preprint arXiv:2205.11487, 2022.
[8] Ming Tao, Hao Tang, Songsong Wu, Nicu Sebe, Xiao- Yuan Jing, Fei Wu, and Bingkun Bao. Df-gan: Deep fu- sion generative adversarial networks for text-to-image synthesis. arXiv preprint arXiv:2008.05865, 2020.
[9] Han Zhang, Jing Yu Koh, Jason Baldridge, Honglak Lee, and Yinfei Yang. Cross-modal contrastive learn- ing for text-to-image generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 833–842, 2021.
[10] Minfeng Zhu, Pingbo Pan, Wei Chen, and Yi Yang. Dm-gan: Dynamic memory generative adversarial net- works for text-to-image synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5802–5810, 2019.