Module 4: AI robustness for Object Detection
Object detection is an important vision task and has emerged as an indispensable component in many vision system, rendering its robustness as an increasingly important performance factor for practical applications. However, object detection models have been demonstrated to be vulnerable against various types of attack, it’s significant to survey the current research attempts for a robust object detector model.
- Introduction
- Adversarial Attacks for Object Detection
- Adversarial Training for Object Detection
- Conclusion
- Reference
Introduction
Object detection is an important computer vision task with plenty of real-world applications such as autonomous vehicles. While object detectors achieve higher and higher accuracy, their robustness has not been pushed to the limit. However, an object detector can be sensitive to natural noises such as sunlight reflections without demonstrating its robustness. Most significantly, it gives malicious parties a way to artificially fool the detector, thus leading to severe consequences. For example, [1] presents that sticking posters on the stop sign can make the object detector ignore it.
There are many ways of adversarially attacking an object detector. One common way is adding adversarial perturbations as visible stickers or patches to the objects either virtually or physically. Such perturbation can successfully fool detectors, but are perceptible to humans. Another way of adversarial attack is adding human-imperceptible perturbations to the image, which can result in detectors failing to detect objects or detect wrong objects.
To improve the robustness of a neural network, one common practice is adversarial training [2, 7]. It achieves robust model training by solving a minimax problem, where the inner maximization generates attacks according to the current model parameters while the outer optimization minimizes the training loss with respect to the model parameters. Zhang et al. [8] extend adversarial training to the object detection domain by leveraging attack sources from both classification and localization. Chen et al. [6] decompose the total adversarial loss into class-wise losses and normalize each class loss using the number of objects for the class. Det-AdvProp [4] achieves object detection robustness with a different approach. It improves the model-dependent data augmentation [5] and fits it into the object detection domain. Different from the previous work, Det-AdvProp considers the common practice of pre-train and fine-tine two-step paradigm. It performs data augmentation during the fine-tuning stage without touching the resource-consuming pre-train stage.
This survey aims at selecting and summarizing object detection research from two perspectives. First, we briefly review the typical structure and the learning objective of object detection. Next, we are going to look into some attack attempts in object detection. Then, we dive into the domain of robust training of object detectors.
Adversarial Attacks for Object Detection
The common practice of generating adversarial perturbations against object detectors is to optimize detection or classification loss. [1] extended PR2 algorithm and utilized it to generate physical adversarial posters and stickers (Fig.1) to attack YOLO v2 object detector. Physical objects with the posters and stickers attached to them will be misclassified. [1] also generated physical adversarial patches which can fool YOLO v2 into detecting non-existent objects.

[11] extended DPatch method into Clipped Attack method to generate adversarial patches against YOLO v3. The adversarial patches can be either attached to an image or placed in the physical world. In both cases, the adversarial patches successfully confused the object detector into focusing on the patches and ignoring detectable objects (Fig.2). Quantitatively, the Clipped Attack method caused YOLO v3 to drop from 55.4 to single digit mAP (mean average precision).
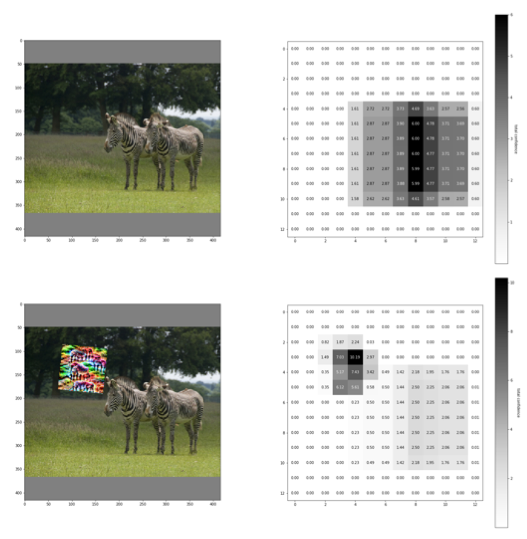

[12] proposed DAG algorithm (Fig.3) to effectively generate visually imperceptible perturbations, and confused the originally correct recognition results in a well controllable manner (Fig.4). An important property of DAG is that it can generate transferable adversarial perturbations. The perturbations can be transferred across different training sets, different network architectures and even different tasks. Consequently, it has caused several object detection networks to drop to single digit mAP. The performance and transferability of DAG has proven the effectiveness of adversarial attack.


Adversarial Training for Object Detection
Improve Robustness from the perspective of dataset
In this subtopic, we will discuss methods that improve the robustness from the perspective of the dataset. In real applications such methods can not only increase the size and diversity of the training set but also provide a simple method to train the model without requiring extra GPU memory. [9]proposed a Patch Gaussian method, which adds a W x W patch of Gaussian noise to the image. This approach first sampled a point within the image as the center of the patch. Then, varying the W and maximum standard deviation of noise could change patch size and noise level. One sample image are shown below to illustrate their method.

The quantitative results on the object detection tasks shows that such a method could also improve the robustness of the detector. A RetinaNet detector with ResNet-50 backbone was trained on the COCO dataset. The COCO validation data was corrupted by i.i.d. Gaussian Noise (=0.25). The model trained with Gaussian Patch achieved mAP of 26.1%, which outperformed the baseline results 11.6%.
[10] improve the robustness by letting the CNN make decisions based on the shape of information. Through extensive experiments, they empirically found that CNN tends to make decisions based on the texture of objects. They overcome this bias and let the CNN consider the shape information by converting the original dataset to images with different styles by using AdaIN Style Transfer. As the figure shows, after applying the AdaIN style transfer, the local texture is no longer maintained and the global shape information tends to be retained.

As the table shows, they train both the ResNet 50 model and Fast Mask-RCNN model based on the different combinations of original and converted dataset. From the table, we can observe the model trained on both original data and converted data achieve the best performance. What’s more, the paper also verifies that training the ResNet 50 model on the style transferred data is more robust to the distortions and noise than the model training on the original dataset. In total, they tested eight kinds of distortions, for example, uniform noise, Contrast, etc. The results indicate that as the distortions increase, the model performance making prediction based on shape information almost improves 20% than the model making decision based the texture.

Improve Robustness by adversarial training
The role of task losses in adversarial training
Although robustness can be improved by adversarial training [2,7], it’s much tricker in object detection. Different from adversarial training on classification tasks which usually has only one loss, object detection tasks consist of two losses (Fig.8). One is the classification loss and the other is localization loss. It’s natural to ask, should we perform the adversarial attack on the sum of them or each of them? Both [3] and [4] experiment with this problem.
[3] attacks the classification loss and the localization loss respectively. The result indicates that two attacks have mutual impacts and the adversarial attacks trailered for one task can reduce the performance of the model on the other task. For example, the attack on the classification not only hurts classification accuracy but also drops localization IoU significantly (Fig.9a). This observation has two indications. First, attacking an object detector is easy. Even attacks on one individual task loss can effectively impede the performance as a whole. Second, we have to study the interaction of these two losses. When generating adversarial examples by attacking both losses, whether the gradients of two losses counteract or enhance will significantly impact the quality of adversarial examples.
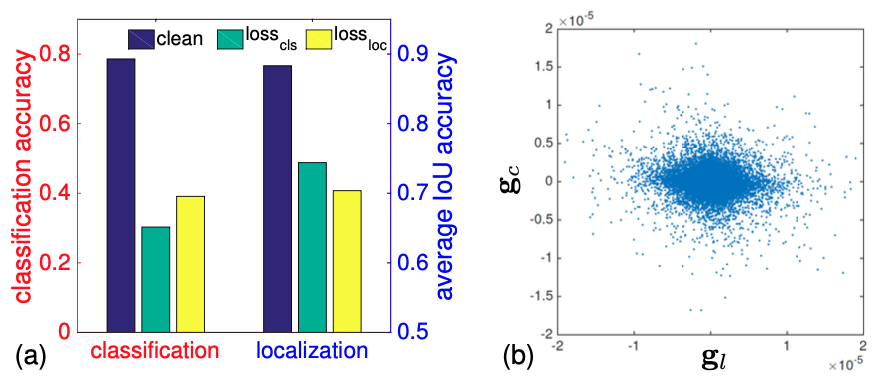
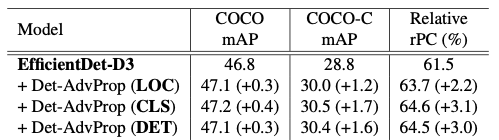
[3] conducts the second experiment to answer this question. In Fig.9b, we can draw two conclusions. (1) the magnitudes of the task gradients are not the same. They spread onto different value ranges, indicating the potential existence of imbalance between two losses; (2) the directions of two gradients are inconsistent (non-diagonal), implying the potential conflicts between them. [4] also does a similar experiment. In Fig.10, LOC, CLS, and DET denote attacks on localization, classification, and both respectively. We can see that the highest mAP is not achieved by the row DET, indicating two losses cancel out each other.
The solution to this is simple. Both [3] and [4] proposed a similar algorithm regarding this issue. Here we present the algorithm in [3]. Intuitively, it attacks localization and classification loss respectively, and only keeps the one that maximizes the total loss. The adversarial output then replaces the original sample in a normal training process.

To improve the algorithm
Based on the algorithm proposed in [3], [4] has two improvements. First, it puts robust object detector training in the context of the pretrain-finetune paradigm. Second, it argues that the adversarial samples have different distributions from the original images. The batch norm layers have to take this discrepancy into account.
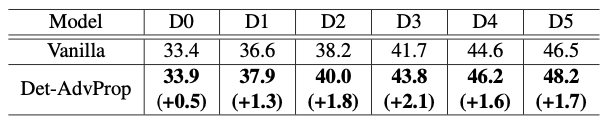
Using adversarial examples to augment data can be taken place in two periods. One is during the pretraining, and the other is during finetuning. [4] argues that although adversarial examples boost up robustness on pretraining, such performance gains cannot transfer after finetuning. Fig.12 shows that pretraining on AdvProp[5] and Noisy Student[11] have similar or even worse performance after finetuning (D2 and D5 are two object detection models where D2 is more light-weighted). Therefore, [4] purposed to move the adversarial data augmentation step from pretraining to finetuning. Fig.13 shows that finetuning 6 models with Det-AdvProp surpasses the vanilla baseline.
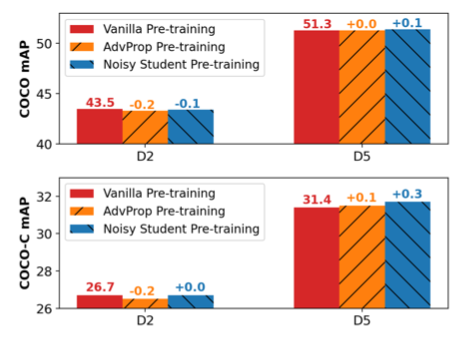
Another improvement to [3] is that [4] draws adversarial examples from another distribution. [4] computes the distribution of adversarial examples in an online manner. Note that adversarial examples for classification loss and classification loss are drawn from the same distribution. Therefore, [4] manages two distributions. One is for the original images and the other is for adversarial examples. One last tiny difference is that [4] does not replace the original image with an adversarial example. Instead, it puts both samples into the normal training process.
In conclusion, both papers demonstrate that traditional adversarial training of classification tasks can be transferred to train a robust object detector. When generating adversarial examples, it’s suggested to attack classification or localization separately and pick the one that maximizes the total loss. In the context of pretraining and finetuning, [4] indicates that augmenting data during finetune step can better preserve the performance gain during pretraining.
Conclusion
In this survey, we go over three object detector attack algorithms, two of which use adersarial patches and the other generates visually imperceptible perturbations through DAG algorithm. In the robustness training part, we first introduced two different data representations, Patch Gaussian and shape-based representation, to improve the robustness to common corruptions without requiring much modification of models and could be simply deployed in real applications. We also introduced two related works on applying adversarial training to object detection domain. To ensure the safety of various real-life applications of object detectors, we believe its robustness is of topmost significance.
Reference
[1] Song, Dawn, et al. “Physical adversarial examples for object detectors.” 12th USENIX workshop on offensive technologies (WOOT 18). 2018.
[2] Madry, Aleksander, et al. “Towards deep learning models resistant to adversarial attacks.” arXiv preprint arXiv:1706.06083 (2017).
[3] Haichao Zhang and Jianyu Wang. Towards adversarially robust object detection. In International Conference on Computer Vision, 2019
[4] Chen, Xiangning, et al. “Robust and accurate object detection via adversarial learning.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021.
[5] Cihang Xie, Mingxing Tan, Boqing Gong, Jiang Wang, Alan L. Yuille, and Quoc V. Le. Adversarial examples improve image recognition. In Computer Vision and Pattern Recognition, 2020.
[6] Pin-Chun Chen, Bo-Han Kung, Jun-Cheng Chen; Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021, pp. 10420-10429
[7] A. Madry, A. Makelov, L. Schmidt, D. Tsipras, and A. Vladu. Towards deep learning models resistant to adversarial attacks. In International Conference on Learning Representations, 2018.
[8] Zhang, Haichao, and Jianyu Wang. “Towards adversarially robust object detection.” Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019.
[9] Lopes, R. G., Yin, D., Poole, B., Gilmer, J., & Cubuk, E. D. (2019). Improving robustness without sacrificing accuracy with patch gaussian augmentation. arXiv preprint arXiv:1906.02611.
[10] Geirhos, R., Rubisch, P., Michaelis, C., Bethge, M., Wichmann, F.A. and Brendel, W., 2018. ImageNet-trained CNNs are biased towards texture; increasing shape bias improves accuracy and robustness. arXiv preprint arXiv:1811.12231.
Vancouver
[11] Mark Lee and Zico Kolter. “On Physical Adversarial Patches for Object Detection.” Computer Vision and Pattern Recognition. 2019.
[12] Cihang Xie, Jianyu Wang, Zhishuai Zhang, Yuyin Zhou, Lingxi Xie, Alan Yuille; “Adversarial Examples for Semantic Segmentation and Object Detection.” Proceedings of the IEEE International Conference on Computer Vision (ICCV), 2017, pp. 1369-1378.