Module 5, Topic: Data collection for Autonomous Driving
Data collection for Autonomous Driving: A survey
Introduction
Autonomous driving nowadays has attracted lots of research interest for its ability to both ease the drivers’ burden and save human lives from accidents. Common tasks for autonomous driving include object detection, both on 2D images and 3D lidar point clouds, semantic segmentation, and localizations. One of the key challenges for real-world applications of autonomous driving is to collect a representative enough dataset to train and test the model behaviors. Different autonomous datasets may vary in data format, size of the training data, collected locations, or weather conditions. Here in this paper, we carefully investigate 6 common datasets for autonomous driving scenarios used as benchmarks for the research purpose.
Autonomous Driving Dataset
We carefully study 6 datasets including widely-used A*3D [2], Waymo [3], HUAWEI ONCE [1] as well as others that have different priorities. We present the publication year, volume of the raw data, sensor layout (LiDARs and cameras) and the annotation type of each dataset in the following Table.
| Dataset | Year | Hours | LiDARs | Cameras | Annotated LiDAR Frames | 3D Boxes |
|---|---|---|---|---|---|---|
| ApolloScape [4] | 2018 | 2 | 2 VUX-1HA laser scanners | 2 front cameras | 144k | 70k |
| Waymo [3] | 2019 | 6.4 | 5 LiDARs | 5 high-resolution pinhole cameras | 230k | 12M |
| A*3D [2] | 2020 | 55 | 1 Velodyne HDL-64ES3 3D-LiDAR | 2 color cameras | 39k | 230k |
| HUAWEI ONCE [1] | 2021 | 144 | 1 40-beam LiDAR | 8 high-resolution cameras | 16k | 417k |
| NuScenes [5] | 2019 | 5.5 | 1 Spinning 32-beams LiDAR | 6 RGB cameras | 40k | 1.4M |
| KITTI [6] | 2012 | 1.5 | 1 Velodyne HDL-64E | 2 color, 2 grayscale cameras | 15k | 80k |
ApolloScape
ApolloScape is the dataset proposed by Baidu for their Apollo project for autonomous driving. The dataset consists of varying conditions and traffic densities, including many challenging scenarios where vehicles, bicycles, and pedestrians move among one another. The trajectory dataset is collected through multiple integrated sensors on the experimenting vehicle. The sensors include 2 LiDar Scanners, 6 Video cameras, and 1 IMU/GNSS position system with an accuracy of 20 ∼ 50mm, roll & pitch accuracy of 0.005°, and heading accuracy of 0.015°. These types of equipment enable the object Detection and Tracking dataset, including about 100K image frames, 80k lidar point cloud, and 1000km trajectories for urban traffic. The demo data and the experimenting vehicle with sensors are shown in Fig. 1.

[Figure 1. Data sample and the testing vehicle for ApolloScape dataset. [4]]
For the data annotation, the whole pipeline is shown in Fig. 2. There are two primary labeling processes in the entire pipeline. The 3D labeling is to analyze the static objects, such as the buildings, trees, and traffic facilities. Moving objects distort in the 3D Point Cloud, so this sub-point cloud data is cleared. The 2D labeling, on the other hand, is to handle the moving object, such as measuring the distance.
[Figure 2. 2D/3D labeling pipeline for ApolloScape dataset. [4]]
One drawback of this dataset is the depth information for the moving objects, which is still missing in the current release. For this dataset, more weather conditions will be integrated in the future.
HUAWEI ONCE
Huawei proposed their dataset ONCE (One millioN sCenEs) together with Huawei Noah’s Ark Lab, Sun Yat-Sen University, and The Chinese University of Hong Kong for 3D object detection in the autonomous driving scenario in 2021. Compared to other benchmarks in the autonomous driving scenarios, ONCE is 20x longer than the current 3D autonomous driving dataset available. The ONCE dataset consists of 1 million LiDAR scenes and 7 million corresponding camera images, varying in different areas, periods, and weather conditions.

[Figure 3. Example scenes for ONCE dataset. [1]]
ONCE dataset is recorded with 144 driving hours. Fig. 3 shows various scenes in the ONCE dataset. For every 3D point cloud scene collected by a high-quality LiDAR sensor, there are approximately 70k points per scene on average. For each 2D image scene, there is 360◦ field of high-resolution view images captured by 7 cameras. Here, ONCE use one 40-beam LiDAR sensor and seven high-resolution cameras mounted on a car to build a data acquisition system. Both sensors can capture data covering 360◦ horizontal field of view near the driving vehicle, and all the sensors are well- synchronized, which checks the calibration parameters and recalibrates the sensor every day.
For annotations, ONCE exhaustively annotated 417k 3D ground truth boxes of 5 categories (car, bus, truck, pedestrian, and cyclist). 3D ground truth boxes were manually labeled from point clouds by annotators using a commercial annotation system. The labeled boxes then went through a double-check process for validness and refinement, which guarantees high-quality bounding boxes for 3D object detection. 769k 2D bounding boxes are also provided for camera images by projecting 3D boxes into image planes.
A*3D
A3D dataset was proposed in 2020 which consists of RGB images and LiDAR data with a significant diversity of the scene, time, and weather. Compared to other benchmarks of the autonomous driving dataset, A3D consists of high-density images, heavy occlusions, and a large number of night-time frames, which tries to narrow the gap between academy research and real-world applications. An illustration of A*3D dataset is in Fig 4.
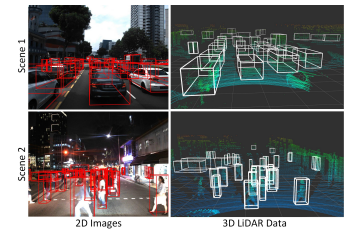
[Figure 4. Example scenes for A3D dataset.* [2]]
With human-labeled 3D object annotations, A3D has 230K 3D bounding boxes in 39, 179 LiDAR point cloud frames, and captured corresponding frontal-facing RGB images. The spatial and time features span nearly the whole of Singapore country, daytime and night time. The traffic scenarios include approximately all the driving scenarios in human’s real-day life, including highways, neighborhood roads, tunnels, urban, suburban, industrial, and car parks. As one of the key differences compared to some other existing benchmark datasets, A3D comprises 30% night-time frames, and 5.9 object instances per frame with a large portion of the annotated objects, which do bring tough challenges for developing more general machine learning models for real-world applications.
Uniformly select 1 LiDAR frame per 5 seconds from 55-hours driving data, which results in 39, 179 frames with their nearest neighbor camera frames, the annotation team marked 3D bounding boxes directly on the LiDAR point cloud for 7 object classes (Car, Pedestrian, Van, Cyclist, Bus, Truck, and Motorcyclist), as long as the objects appear in the corresponding camera FoV. Each bounding box is associated with 2 attributes - occlusion and truncation where occlusion is categorized into 4-levels and truncation contains 3-levels. 2D bounding boxes were generated by projecting 3D bounding boxes in the point cloud with the accurate camera-LiDAR calibration
Waymo
Waymo Open Dataset was proposed in 2020 by Waymo and Google. Generally, the Waymo dataset consists of 1150 scenes spanning 20 seconds. With well synchronized and calibrated high-quality LiDAR and camera data, the Waymo dataset consists of captured data across a range of urban and suburban geographies. Compared to other existing benchmark datasets in autonomous driving, it is much more diverse than the largest camera-LiDAR dataset based on the proposed geographical coverage metric. Example data is shown in Fig. 5.
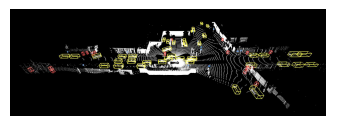
[Figure 5. Example scenes for Waymo dataset. [3]]
Waymo dataset uses five LiDAR sensors and five high-resolution pinhole cameras to record all the sensor data to form a dataset. Waymo dataset contains a large number of high-quality, manually annotated 3D ground truth bounding boxes for the LiDAR data, and 2D tightly fitting bounding boxes for the camera images. All ground truth boxes contain track identifiers to support object tracking. In addition, researchers can extract 2D camera boxes from the 3D LiDAR boxes. Waymo dataset contains around 12 million LiDAR box annotations and around 12 million camera box annotations, giving rise to around 113k LiDAR object tracks and around 250k camera image tracks. Waymo dataset has two levels for difficulty ratings, where the metrics for LEVEL 2 are cumulative and thus include LEVEL 1. The criteria for an example to be in a specific difficulty level can depend on both the human labelers and the object statistics. All annotations were manually created and subsequently reviewed by trained labelers using production-level labeling tools.
KITTI
KITTI is one of the most important test sets mainly for image processing technology in the field of automatic driving, is mainly used in autonomous perception and forecast. Localization and SLAM are also involved in the dataset. The researchers find the limitation in some algorithms that will be out of work in the real-life scenario. Thus they set the KITTI’s goal to be providing a large dataset of real-world scenarios that can be used to measure better and test algorithm performance.
Here are the some of vital benchmarks in the KITTI:
Stereo. Based on image stereovision and 3D reconstruction, restoring structure from one image is fuzzy in nature, and 3d structure is generally recovered from multiple images at different angles. This is very helpful in autonomous driving scenarios, such as getting the shape of the car, the shape, the surrounding environment, etc.
Flow. Optical flow is the concept of object motion detection in the field of view. A term used to describe the motion of an observed object, surface, or edge resulting from motion with respect to the observer. Application areas include motion detection, object segmentation, contact time information, extended computational focus, luminance, motion compensation coding, and stereo parallax measurement.
Sceneflow. A scene flow is a dense or semi-dense 3D playground of a scene that moves completely and partially relative to the camera. There are many potential applications for scenario flows. In robotics, it can be used for autonomous navigation and/or manipulation in dynamic environments where prediction of the movement of surrounding objects is required. In addition, it can complement and improve state-of-the-art visual ranging and SLAM algorithms, which are often assumed to work in rigid or quasi-rigid environments. On the other hand, it can be used for robot or human-computer interaction, as well as virtual and augmented reality.
In the future, the researchers plan to include visual SLAM with loop-closure capabilities, object tracking, segmentation, structure-from-motion, and 3D scene understanding into the evaluation framework. This plan will boost the performance of the sensing and localization of the angstrom.
NuScenes
In the field of 3D target detection, there are several datasets that are widely used. In addition to KITTI, nuScenes, is also very common. NuScenes collected data in Boston and Singapore using vehicles equipped with a spinning LIDAR, five Long Range RADAR sensors, and six cameras. According to official documentation, the amount of data annotated is more than seven times higher than KITTI. The whole framework is shown in figure 5.
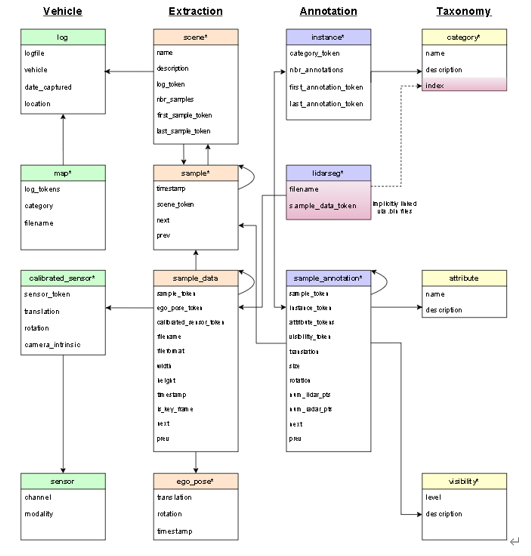
[Figure 5. FrameWork of nuScenes. [5]]
The nuScenes dataset samples well-synchronized keyframes (images, LIDAR, RADAR) at 2Hz and is annotated by Scale. All objects in the nuScenes dataset carry a semantic category, along with 3D bounding boxes and attributes for each frame in which they appear. Compared with 2D bounding boxes, the position and orientation of objects in space can be accurately inferred.
From left to right are Vehicle, Extraction, Annotation and Taxonomy.
The lines from top to bottom represent the various levels of objects. In the case of Extraction, a scene represents the 20-second continuous frame sequence extracted from the log (A scene is A 20s long sequence of frames extracted from A Log.), and A sample represents A 2Hz annotated keyframe at 2Hz. (A sample is an annotated keyframe at 2Hz.) That is, A-frame extracted from A scene. Sample_data further represents sensor data at a time point (TIMESTAMP), such as images, point clouds, or Radar. Each sample_data is associated with a sample, and if its IS_KEY_frame value is True, its timestamp should be very close to its corresponding keyframe, and its data should be close to the keyframe time.
Conclusion
Autonomous vehicles have several advantages beyond traditional vehicles, such as safety and traffic planning. However, a series of recent driverless accidents has shown that it is not clear how an artificial driver-awareness system can avoid some seemingly obvious mistakes. Thus multiple datasets have been proposed and developed to overcome the potential problems. Different datasets have specific targets and aim to solve problems under different scenarios. This small survey lists several datasets and explains their working mechanisms. In the future, in our group’s opinion, more diverse technology will be involved in the datasets, such as the SLAM, robust control, etc. Autonomous driving may finally be involved in our daily life and change everyone’s life.
Reference
[1] Mao J, Niu M, Jiang C, et al. One million scenes for autonomous driving: Once dataset[J]. arXiv preprint arXiv:2106.11037, 2021.
[2] Pham Q H, Sevestre P, Pahwa R S, et al. A* 3D dataset: Towards autonomous driving in challenging environments[C]//2020 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2020: 2267-2273.
[3] Sun P, Kretzschmar H, Dotiwalla X, et al. Scalability in perception for autonomous driving: Waymo open dataset[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2020: 2446-2454.
[4] Huang X, Cheng X, Geng Q, et al. The apolloscape dataset for autonomous driving[C]//Proceedings of the IEEE conference on computer vision and pattern recognition workshops. 2018: 954-960.
[5] Caesar H, Bankiti V, Lang A H, et al. nuscenes: A multimodal dataset for autonomous driving[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2020: 11621-11631.
[6] Geiger A, Lenz P, Stiller C, et al. Vision meets robotics: The kitti dataset[J]. The International Journal of Robotics Research, 2013, 32(11): 1231-1237.