Module 8: Superhuman AI and knowledge generation
How do self-played models such as AlphaZero obtain knowledge? Can we uncover novel strategies from those models that surpass humans? In this survey, we present the recent advences in related fields.
- A Gentle Introduction
- Knowledge Discovery in Chess
- Knowledge Generated in Video Games
- Advancing Human Understanding Using the Discovered Knowledge
- Discussion
- Conclusion
- Reference
A Gentle Introduction
Superhuman AI models are created with superhuman capabilities in their domain. Moreover, some of them are trained via self-play, indicating that these AI models might have obtained the domain knowledge differentely from us. For example, AlphaZero achieves superhuman performance in chess, Go, and Shogi[5] without being exposed to one single human play record. How do self-played models such as AlphaZero obtain knowledge? Can we uncover novel strategies from those models that surpass humans? In this survey, we present the recent advences in related fields.
Specifically, we focus on introducing the various approaches and discoveries when probing the knowledge generated by superhuman AI systems, rather than talking the architectures of these investigated models themselves. Namely, we assume the readers have prior knowledge about the architectures of famous superhuman AI models such as AlphaZero and AlphaStar. However, we also talk about the details of supervised/reinforcement learning when the neural networks and the learning paradigm play a role in the process of knowledge generation.
This survey consists of four parts. In the first section, we introduce in detail several works that examine chess concepts as they emerge in the AlphaZero network, the behavioral changes, and impact on the aggregate value assessment. In the second section, we study the knowledge generated in video games, including StarCraft II, Gran Turismo, Dota 2, and Atari. Since the probing of video playing agents is not as thorough as the the chess game agent, the second section is broader in scope but shallower individually. In the third section, we show how knowledge can be useful for humans in chess and poker. Lastly, we share our thoughts on the challenges in related fields.
Knowledge Discovery in Chess
Chess long been a “Drosophila” of AI research [1], i.e., a prototype game for examining novel AI architectures. Among all the chess engines that plays close to human level, AlphaZero [8] is trained via self-play (has never been exposed to human data), examines fewer positions, and performs at a superhuman level. Since it has never seen human-generated data yet exceed human performance, the AI research community is naturally interested in probing AlphaZero for human-understandable concepts [2,3,4,5,6,7] and seek for evidences to enhance the human knowledge [3,6,7]. Specifically, this section revolves around [6] since it is most comprehensive.
Where, When & Which Concepts does AlphaZero learn?
Two concurrent works [5, 6] both attemp to answer this same question. If we view each ResNet [11] block in the AlphaZero neural network as a layer, [6] probes the activations of each layer for a broad range of human chess concepts using pre-specified functions which encapsulate a particular piece of domain-specific knowledge. Those pre-specified functions, such as material, imbalance, mobility, king safety, are directly adopted from the public Stockfish’s evaluation function. Then, the authors map the input feature ($d_0$ dimensional vector $z^0$) into a single real value $c(z^0)$. Therefore, the probing can be transformed into learning a set of linear regression parameters {$w$, $b$} by minimizing the empirical mean squared error between $c(z^0)$ and $w^T z^{lt} + b_{lt}$, where $z^{lt}$ is the activations in the $l$-th layer at training step $t$. The authors then visualize this concept learning with the what-when-where plots, as shown in Figure 1.
 Figure 1: What-when-where plots for a selection of Stockfish 8 and custom concepts. [6]
Figure 1: What-when-where plots for a selection of Stockfish 8 and custom concepts. [6]
From Figure 1, we see that the information related to human-defined concepts of multiple levels of complexity, is being learned over the course of training. Many of these concepts are computed over the course of multiple blocks.
Similarly, [5] investigate AlphaZero’s representations but in Hex (a game in which two players attempt to connect opposite sides of a rhombus-shaped hex board) using both model probing and behavioral tests. While both [5] and [6] use human defined concepts and investigate AZ’s representations, [5]’s investigation is more in-depth thanks to the easier problem setting in Hex. The main findings (as shown in Figure 2) are that 1)concepts related to short-term end-game planning are best encoded in the final layers of the model, whereas concepts related to long-term planning are encoded in the middle layers of the model; and 2) improvements in behavioral tests occur before improvements in probing accuracy, which align with the findings in [6].
 Figure 2: Changes in Hex concept representation and use during training.[5] The checkpoint at which behavioral tasks improve are blue, and converge are yellow. The checkpoint at which probing tasks improve are pink, and converge are green. Improvements in board structure are orange, and convergence, purple.
Figure 2: Changes in Hex concept representation and use during training.[5] The checkpoint at which behavioral tasks improve are blue, and converge are yellow. The checkpoint at which probing tasks improve are pink, and converge are green. Improvements in board structure are orange, and convergence, purple.
Move-level Behaviors
Chess players adopts algebraic notation for moves. Each move of a piece is indicated by the piece’s uppercase letter, plus the coordinate of the destination square. For example, Be5 (bishop moves to e5), Nf3 (knight moves to f3). For pawn moves, a letter indicating pawn is not used, only the destination square is given. For example, c5 (pawn moves to c5).
Behavioral stylometry means predicting the identity of a player from the moves they played in a given set of games. [3] study this problem extracts move-level features from AI agents such as AlphaZero [8] and Maia [2], and then adopts transformer based models to aggregate information from move-level to game-level and player-level. Their proposed method achieves 98% accuracy in identifing a player fromn among thousands of candidate players. While this work does not explictly compare the moves of AlphaZero against other players, the high success rate of human behavioral stylometry by training on the moves extracted self-play AI models indicate that these two worlds share a lot in common.
Move-level Behavioral Changes. Another interesting finding is a marked difference between AlphaZero’s progression of move preferences through its history of training steps, and what is known of the progression of human understanding of chess since the 15th century [6]. As the researchers in [6] point out,
“AlphaZero starts with a uniform opening book, allowing it to explore all options equally, and largely narrows down plausible options over time. Recorded human games over the last five centuries point to an opposite pattern: an initial overwhelming preference for 1.e4, with an expansion of plausible options over time.”
Figure 3 shows the opening move preference for White at move 1. Most of the earliest recorded human games seem to feature 1. e4 as the opening move. On the other hand, AlphaZero simultaneous in comparison, rather than relying mainly on a single initial move before branching into alternatives, which seems to be the case in early human play.
 -
Figure 3. A comparison between AlphaZero’s and human first-move preferences over training steps and time. [6]
-
Figure 3. A comparison between AlphaZero’s and human first-move preferences over training steps and time. [6]
In addition, [11] takes a stab to interpret chess moves by learning to generate move-to-move comments as a natural language generation task. However, the ground truth data are all human written and thus the model is only trained to approximate human commentary texts.
Is there a “unique” good chess player?
Certain opening strategies have been predominately favored by chess players throughout the human historical records. Does it happen by chance or not? While it is impossible to replay human history, the researchers in [6] train different versions of AlphaZero with different random seeds. Half of them converges to the Berlin defense 3… a6, while the other half strongly prefer the more typical 3… Nf6, indicating that there is probably no “unique” good chess player.
Knowledge Generated in Video Games
In addition to chess, researchers also tried probing the patterns of superhuman AI models in video games such as StarCraft II and Gran Turismo.
AlphaStar and StarCraft II
AlphaStar, a computer program that plays the video game StarCraft II, is a real-time strategy game that requires sophistication as its player needs to control hundreds of units.[12] This game includes non-transitive strategies and counter-strategies which create obstacles to discovering novel strategies for researchers.[12] Problems such as partial observability, imperfect information, large action space, and potential strategy cycles must be overcomed.
Supervised and Reinforcement Learning
During the supervised learning process, the statistics such as $z$ which has each player’s build order (i.e., first 20 constructed buildings and units), units, buildings, effects, and upgrades are represented in the game.[12] The inclusion of statistics $z$ enables AlphaStar to extract knowledge from human replays during supervised learning. AlphaStar is instructed to imitate human behaviors during this process, leading to knowledge discovery of human actions.
Reinforcement learning is also used to improve the performance of AlphaStar after supervised learning. The value fuction $V_{\theta}(s_{t}, z)$ is used to predict $r_{t}$ which is used to update the policy $\pi_{\theta}(a_{t}\mid s_{t},z)$.[12] $s_{t}$ is the observation AlphaStar has which serves as the input to the AlphaStar. $a_{t}$ is the action AlphaStar has in response to the input $s_{t}$. The statistics z is again used in this process to discover novel strategies.
The Statistics $Z$
As strategic diversity is maintained during reinforcement training, researchers from [12] have also found that the use of human data is essential to achieving good performance. Figure 5(e) from [12] shows that the inclusion of statistics $z$ contributes most to the improvement of performance, indicating that AlphaStar benefits from the knowledge discovery from human replays.
Now that we know the supervised learning approach in AlphaStar training enables AlphaStar to learn human knowledge. The statistics $z$, in particular, ensures the learning of novel strategies during supervised learning and reinforcement learning. Furthermore, the inclusion and exclusion of statistics z enable AlphaStar to discover new novel strategies.[12]
In Figure 4, AlphaStar final (on the right) build significantly more “Dark Templar”, “Disruptor”, and “Phoenix” than AlphaStar Supervised. Fewer “Dark Templar” and “Zealot” are built by AlphaStar Final. AlphaStar Supervised is the model of AlphaStar after supervised learning; AlphaStar Final is the model of AlphaStar after multi-agent learning. Because AlphaStar Supervised intends to learn human strategies, it highly resembles human behaviors. Thus, AlphaStar Supervised can be used as a baseline for the discovery of novel strategies and AlphaStar Final can show the strategies learned from reinforcement learning and multi-agent learning. The comparison between AlphaStar Supervised and AlphaStar final shows what novel strategies are learned. As novel strategies in StarCraft II relates to the units built in the game, the differences in built units between AlphaStar Supervised and AlphaStar Final depict the learning of novel strategies for AlphaStar.

Figure 4. Units built by Protoss AlphaStar Supervised (left) and AlphaStar Final (right) over multiple self-play games.[12]
However, AlphaStar also suffers from refining its “micro-tactics” while ignoring the whole concept of the game. For example, AlphaStar would execute a precise sequence of instructions to construct and use air units[12]. Even though AlphaStar can complete those “micro-tactics” better than humans, its lack of the overall game understanding still makes it vulnerable to human players.
Ablations for Key Components
Multi-Agent learning is used to train AlphaStar to resolve cycles encountered during self-play training and to discover a wider range of strategies.[12] Three types of agents populate the League to enhance the training. Main agents are most important to AlphaStar as the goal of multi-agent learning is to improve the performance of main agents. Main exploiters are also part of the League and it discovers the weaknesses of main agents. Main agents, after training with main exploiters, can become more robust. League exploiters, the last important part of the League, are able to discover weaknesses in all agents in the League, thus, it can improve the robustness of the whole League.
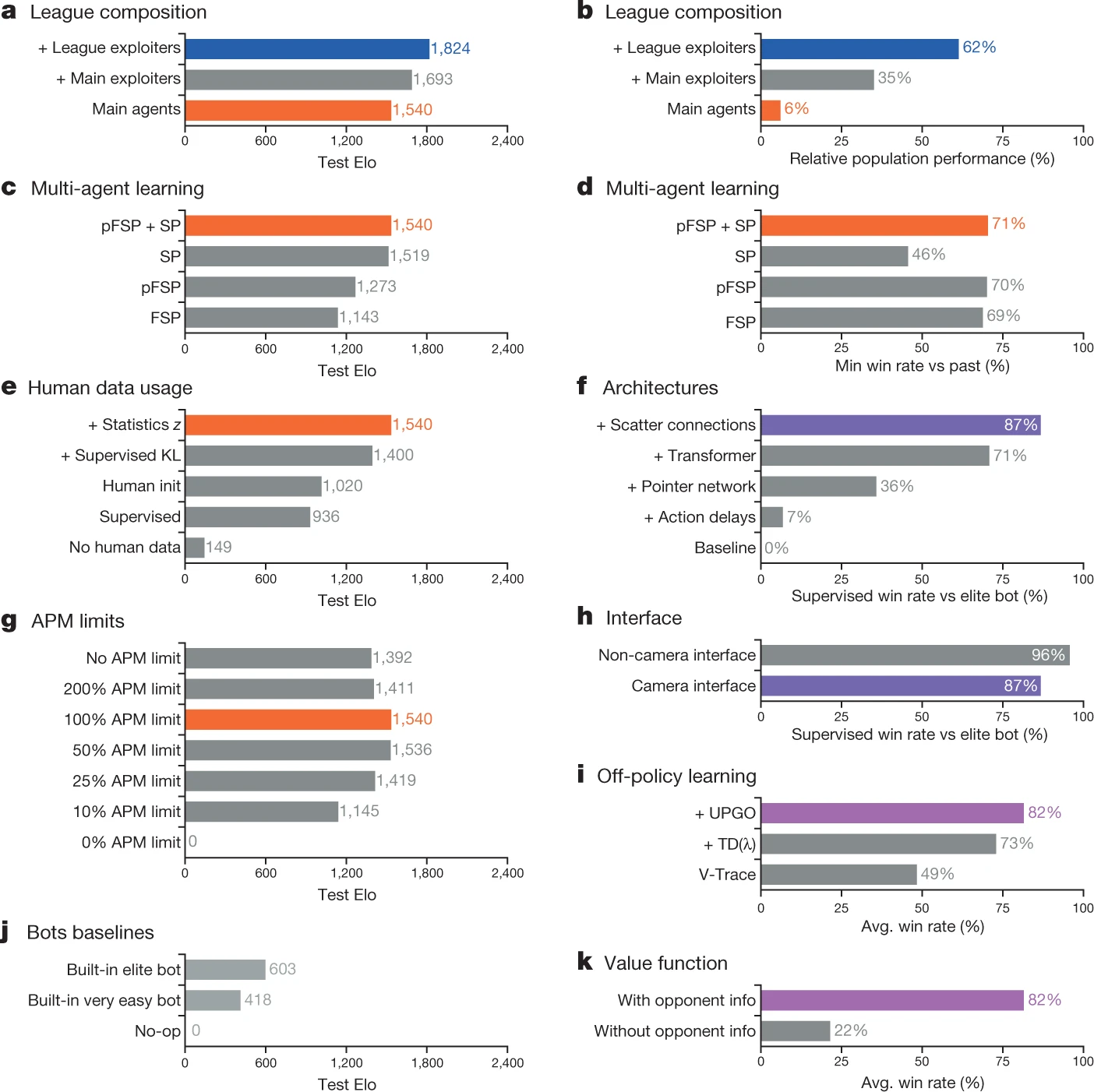
Figure 6. Ablations for key components of AlphaStar[12]
Even though main exploiters and league exploiters can discover strategies against the main agent quickly, these agents suffer from low robustness upon exploitation. However, the main agent trained can learn strategies with better robustness. Thus, with multi-agent learning and the inclusion of three different kinds of agents in the League, AlphaStar is able to extract more robust knowledge from StarCraft II.
Gran Turismo
Gran Turiso is another example of video game that requires real-time decisions and interactions with humans.[14] Researchers created Gran Turismo Sophy (GT Sophy), a champion-level racing agent, to compete with top human drivers.
Knowledge Modelled in Deep Reinforcement Learning
Similar to AlphaStar, the training of GT Sophy also utilizes deep reinforcement learning. A revised quantile regression soft actor-citric (QR-SAC) algorithm is used to let the actor learn the policy. This actor-citric approach will learn a policy (actor) that “selects an action on the basis of the agent’s observations” and a value function (citric) that “estimates the future rewards of each possible action.”[15] Furthermore, the agent has given a progress reward [16] for its speed around the track and penalties when it “went out of bounds”, “hit a wall”, or “lost traction”. These instant rewards enable the agent to rapidly adopt the policy so that it can go fast while staying on the road. GT Sophy is able to discover novel strategies in this process as it will get rewarded when it did things correctly.
Knowledge Modelled in Multi-agent Learning
GT Sophy also utilizes multi-agent training to improve its performance. Multi-agent traning is used due to similar reasons that AlphaStar uses multi-agent traning. Training against itself would make the agent lose the preparation for future dangers. For example, when there is a hard corner in the front, human drivers would break earlier than the agent. Even though the time difference is very small, it can lead to one driver losing control of one’s car. This cause-and-effect setting in which one player’s choices causing another player to be penalized is rarely seen in other games. This setting is also non-existent in zero-sum games such as chess. [14] In order to ensure the policy an agent learned will actually benefit that agent, a mixture of opponents is used by researchers from [14]. The inclusion of various agents enables GT Sophy to learn more diverse strategies. The discovery of knowledge also happens during this process. With more agents involves in the training, GT Sophy is able to detect its weaknesses and resolves them.
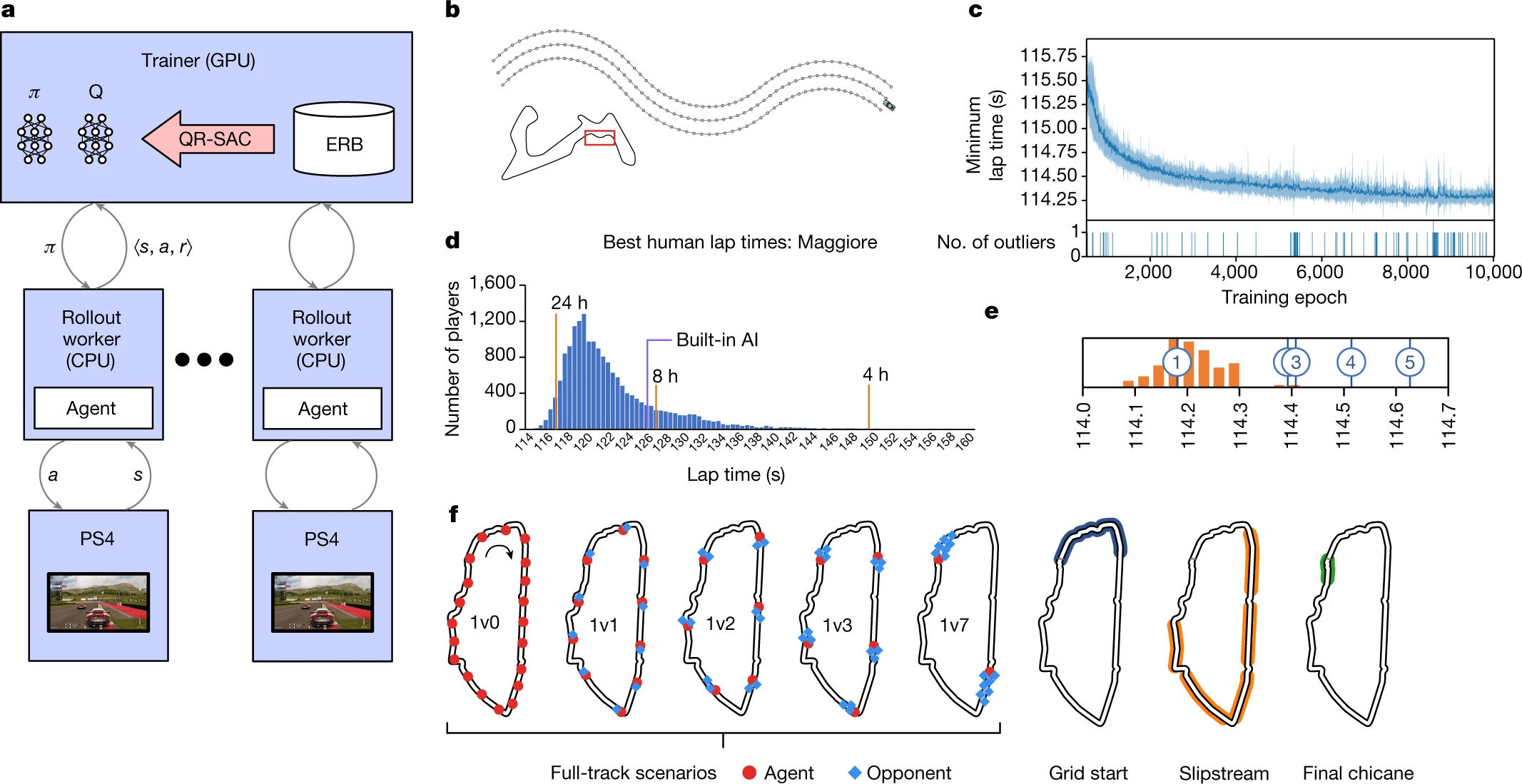 Figure 7. The Training Process of GT Sophy [14]
Figure 7. The Training Process of GT Sophy [14]
The cooperation of various drivers also makes the learning of knowledge very difficult. It’s hard to reproduce the “cooperation” between one car and another. One example from [14] is a slingshot shot. It requires a car in the slipstream of an opponent on a long straightway. This condition would be hard to occur naturally. Researchers utilize human knowledge to solve this problem in which a retired competitive GT player would identify “a small number of race situations” that are important on each track. The graph f from [14] shows the scenarios of these race conditions. With the help of human knowledge, GT Sophy is able to learn these race conditions. Furthermore, the inclusion of different track configurations (zero, one, two, three, or seven nearby opponents) ensures the robustness of the skill as the relative car arrangements in these positions are varied.
Thus, GT Sophy is able to extract human knowledge from reinforcement learning and multi-agent learning. Even at the time when GT Sophy can’t discover knowledge by itself, expert’s involvement empower the program to novel strategies by forcing GT Sophy to go through certain tracks. However, given so many processes trying to make this agent better, this agent still doesn’t perform that well when learning complex strategies that require the thinking of multiple future steps and the inclusion of other players. This can be partially due to its over-focus on micro-strategies. The focus on micro-strategies is also seen in AlphaStar in [12]. Similar weaknesses shows that the current multi-agent training is still imperfect.
Other Video Games
Knowledge discovery also occurs in other Superhuman AI models such as the program playing Atari and Dota 2 game. In these games, deep reinforcement learning is also employed to improve the performance of AI model.
Atari
Atari is an example of computer game that has simple game interface and easy actions. Researchers have created the first deep reinforcement learning model on Atari game. The training process is different from works mentioned previously as the experiments are done over 9 years ago. Knowledge are discovered in the training process as human replays are the input to the training. The input of human replays are similar to other knowledge discovery AI models. It can be concluded that human inputs in video games is a easy way to initialize the agent.
Dota 2
Dota 2 is another example of computer game that has complex action space and imperfect information. The goal of the game is to destory the enemy’s base.[18] The team from [18] builds an AI model, OpenAI Five, with deep reinforcement learning to play Dota 2.
However, even though OpenAI Five is able to beat best human players in multiple games such as winning the game against the Dota 2 world champions in 2019 [18] it has different preferences comparing to humans. The knowledge discovery from OpenAI Five enables it not only to follow human knowledges, but also creates its own strategies. Following the human, OpenAI Five would do actions such as “placing a high value on the hero Sniper”.[18] This is a common human bahavior. However, OpenAI Five also disagrees with human knowledge by placing a “low value on Earthshaker”.[18] The mix of human behaviors and behaviors that are rare to humans also exists in AlphaStar. The similarities between AlphaStar and OpenAI Five shows that there are still some weaknesses in the current Superhuman AI model.
Advancing Human Understanding Using the Discovered Knowledge
We now have access to automatically generated high-quality statistical knowledge beyond human expert intuition in many fields. This section lists several interesting findings.
Chess
The iconic move 37 in the first game of the historical Lee Sedol vs. AlphaGo match showed a new kind of machine creativity.The game is not over yet for humans. Existing AI techniques can benefit human chess players from various aspects. Recently, [7] emphasizes the neccesity of pairing human skills (e.g., high-level reasoning, counterfactuals, explanations) with an unlimited supply of high-quality statistical experiments as a new situation. Below, we introduce the recent advancement from two aspects.
- Algorithms and Human Behavior
-
[2] repurpose the AlphaZero deep neural network framework to predict human actions, rather than the most likely winning move. Instead of training on self-play games, a new model caleed Maia is trained on human games recorded in datasets of online human play to encourages the policy network to learn human favorable plays. Moreover, this new model does not conduct any tree search – the policy network is solely responsible for the prediction.
- [2] finds that Maia “displays a type of behavior qualitatively different from these traditional chess engines: it has a natural parametrization under which it can be targeted to predict human moves at a particular skill level.” Specifically, they show by training 9 separate Maia models, one for each bin of games played by humans of a fixed and discretized skill level, each Maia model peaks in performance near the rating bin it was trained on. Such a discovery is fundamental to designing artificial intelligence systems targeting at a specific skill level, which might be useful in building future AI teachers for different levels of human students.
- Similarly, [3] develops a transformer-based approach to behavioral stylometry in the context of chess. Their resulting embeddings reveals a structure of human style in chess, with players who are stylistically similar clustering together in the space.
- Exploring Chess Models with Unsupervised Methods
In order not to be confined to labeled data of human concept, [6] takes unsupervised approached involving matrix decomposition as dimension reduction and correlation analysis.
We explain the process of non-negative matrix factorization (NMF) as a relatively straight forward example. Recall that we count a ResNet ‘block’ as a layer, and a layer $l$’s representation is $\mathbf{z}^{l} \in \mathbb{R}^{H \times W \times C}=\mathbb{R}^{8 \times 8 \times 256}$. We want to approximate $z^l$ by compressing $z^l$ to $\Omega$, where $\hat{\mathbf{z}}^{l} \approx \Omega \mathbf{F}$, $\Omega \in \mathbb{R}^{H \times W \times K}$ (K«C), and $\mathbf{F}$ is a shared matrix throughout all layers. The NMF factors and their weights are found by minimizing the following term:
\(\mathbf{F}^{*}, \boldsymbol{\Omega}_{\text {all }}^{*} =\min _{\mathbf{F}, \boldsymbol{\Omega}_{\text {all }}}\left\|\hat{\mathbf{Z}}^{l}-\boldsymbol{\Omega}_{\text {all }} \mathbf{F}\right\|_{2}^{2} (\mathbf{F}, \boldsymbol{\Omega}_{\text {all }} \geq \mathbf{0})\) \(\boldsymbol{\Omega}^{*}=\min _{\boldsymbol{\Omega}}\left\|\hat{\mathbf{z}}^{l}-\boldsymbol{\Omega} \mathbf{F}^{*}\right\|_{2}^{2}\)
To understand the $88K$-dimension NMF factors, the researchers overlay the K columns onto the input $z^0$. The selected visualization in Figure 8 shows some illustrative cases of how much NMF factor K contributes to each neuron’s representation. The factors shown in Figure 4a and Figure 4b show the development of potential move computations for the player’s and opponent’s diagonal moves respectively. We can see from Figure 4a that only three squares or fewer highlighted in the first move, which is consistent with the convolutional structure that all computations from one layer to the next involve only spatially adjacent neurons.
 –
–
Figure 8. Visualisation of NMF factors in a fully-trained AlphaZero network, showing development of threats and anticipation of possible moves by the opponent, as well as a factor that may be involved in move selection. [6]
Figure 4c shows a more complex factor in layer 3: a count of the number of the opponent’s pieces that can move to a given square (darker weights indicates more pieces can move to that square). This factor is likely to be useful in computing potential exchanges, and indicates that AlphaZero is also considering potential opponent moves even early in the network. Figure 4d appears to show potential moves for the current player - darker squares indicate better moves (for instance the opponent’s hanging queen on d2).
Our critics. Due to space limit, we omit the correlation analysis in [6]. However, both unsupervised proposed methods are confined to activation layers. What’s more, it requires strong assumptions of spacial alignment for visualization on the chess board. All these means that the whole process requires human expert labor to interpret and spot a few human understandable illustrations from hundred piles of visualized ones. In other words, these approaches are far from scalable. In addition, although unsupervised approaches are introduced to go beyond labeled human concept, the discoveries are inevitably confined to human concepts when visualization takes place.
Poker
Nash equilibria have been proven to difficult to find in large imperfect-information games such as multi-player poker, than zero-sum two-players game such as chess. Notably, [9] presents Pluribus, an AI that is stronger than top human professionals in six-player no-limit Texas hold’em poker through simialr self play and MCTS. Figure 9 is a simplified diagram of the real-time search in Pluribus.
By looking at the strategy stored in Pluribus, the authors find out that Pluribus aligns with the conventional human wisdom that limping (calling the “big blind” rather than folding or raising) is suboptimal for any player, except the “small blind” player who already has half the big blind in the pot by the rules, and thus has to invest only half as much as the other players to call. In addition, while Pluribus initially experimented with limping when computing its blueprint strategy offline through self play, it gradually discarded this action from its strategy as self play continued.
 –>
Figure 9. Real-time search in Pluribus. For simplicity the subgame shows just two players [9].
–>
Figure 9. Real-time search in Pluribus. For simplicity the subgame shows just two players [9].
However, Pluribus disagrees with the folk wisdom that “donk betting” (starting a round by betting when one ended the previous betting round with a call) is a mistake – Pluribus does this far more often than professional humans do.
Comments
In this genre of problem we are no longer interested in maximazing the absolute performance, instead, we ask whether we can utilize the AI models (most of which has never seen human data at all) to enhance human domain knowledge.
There is a lot we don’t understand about achieving this ambitious goal. To the best of my knowledge, existing works are confined to verifying (and challenging against) certain moves or domain knowledge that human already possess. Evidences can be found in all aforementioned literatures in this section – none is able to discover unimagined, novel tatics to enhance human capability from a brand new aspect.
For instance, in what form shall the knowledge be mined from AI models? A saying going that “Knowledge has perceivable limits”. It’s challenging to discover anything beyond the realm of human perceivable intellect. Or can we? Probably just as [2, 7] said, pairing human skills with an unlimited supply of high-quality statistical experiments is a more practical way to go.
Discussion
Why are most superhuman AI models game playing agents?
In this survey, we focus on the various approaches and discoveries when probing superhuman AI systems. Coincidentally, a large proportion of our investigated systems are game playing agents, i.e. RL-based models trained to learn to play competitive games. While we hope to write a comprehensive survey by including many other tasks including common CV and NLP taskss, we can hardly find sufficient resources. Such a phenomenon raises our attention.
Indeed, the superiority of game systems can be readily demonstrated, for example by defeating legendary human players. On the other hand, for other tasks such as image classification, human annotations are often treated as a ground truth, which implicitly assumes the superiority of the human over any models trained on human annotations. We thereby argue that it is important for the AI community to jump out of the box of crowdsourcing, and test the performance of many models from fresh eyes. For example, [10] is among the first to evaluate the performance of classifiers with respect to a genuine and unobersevred oracle, even though querying the oracle is expensive and/or impossible. It also shows that under several loose assumptions, a number of classification models from recent years (e.g., BERT-large and StructBERT for sentiment classification and LM-Pretrained Transformer for natural language inference) are with high probability superhuman. We look forward to seeing more research conducted under this line.
Conclusion
We introduced the current progress of interpreting the knowledge obtained by superhuman AI models and the frontiers of advancing human understanding with this discovered knowledge. While the knowledge discovery in chess playing agents receive mostly promising results, the discovery process in video games such as StarCraft II, Gran Turismo, and Dota 2 also manifests the weaknesses of existing superhumanAI models. It remains challenging to uncover and understand superhuman AI models and “translate” those discoveries to human percivable intellects.
Reference
[1] Kasparov, Garry. “Chess, a Drosophila of reasoning.” Science. 2018.
[2] McIlroy-Young, Reid, et al. “Aligning superhuman ai with human behavior: Chess as a model system.” Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2020.
[3] McIlroy-Young, Reid, et al. “Detecting Individual Decision-Making Style: Exploring Behavioral Stylometry in Chess.” Advances in Neural Information Processing Systems 34,2021
[4] Sanjaya, Ricky, Jun Wang, and Yaodong Yang. “Measuring the non-transitivity in chess.” Algorithms 15.5 (2022).
[5] Forde, Jessica Zosa, et al. “Where, When & Which Concepts Does AlphaZero Learn? Lessons from the Game of Hex.” AAAI Workshop on Reinforcement Learning in Games. 2022. [6] McGrath, Thomas, et al. “Acquisition of Chess Knowledge in AlphaZero.” arXiv preprint arXiv:2111.09259 (2021).
[7] Egri-Nagy, Attila, and Antti Törmänen. “Advancing Human Understanding with Deep Learning Go AI Engines.” Proceedings MDPI, 2022.
[8] Silver, David, et al. “A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play.” Science. (2018).
[9] Brown, Noam, and Tuomas Sandholm. “Superhuman AI for multiplayer poker.” Science, 2019.
[10] Xu, Qiongkai, Christian Walder, and Chenchen Xu. “Humanly Certifying Superhuman Classifiers.” arXiv preprint arXiv:2109.07867 (2021).
[11] He, Kaiming, et al. “Identity mappings in deep residual networks.” European conference on computer vision. 2016.
[12] Vinyals, Oriol, et al. “Grandmaster Level in Starcraft II Using Multi-Agent Reinforcement Learning.” Nature. 2019. https://doi.org/10.1038/s41586-019-1724-z.
[13] Hinton, Geoffrey, Oriol Vinyals, and Jeff Dean. “Distilling the knowledge in a neural network.” arXiv. 2015.
[14] Wurman, Peter R., et al. “Outracing champion Gran Turismo drivers with deep reinforcement learning.” Nature. 2022.
[15] Haarnoja, Tuomas, et al. “Soft actor-critic algorithms and applications.” arXiv. 2018.
[16] Fuchs, Florian, et al. “Super-human performance in gran turismo sport using deep reinforcement learning.” IEEE Robotics and Automation Letters. 2021.
[17] Mnih, Volodymyr, et al. “Playing atari with deep reinforcement learning.” arXiv. 2013.
[18] Berner, Christopher, et al. “Dota 2 with large scale deep reinforcement learning.” arXiv. 2019.ct detection.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.